- Submission : 2019
- Conference : CVPR
- Paper Link : arxiv.org/abs/1812.04948
Keywords
- Style-based
- Disentanglement
- Interpolation
- Understanding GAN
Contribution
- High level attribute의 scale-specific control이 가능하다.
- Disentanglement, interpolation을 향상시켰고, 이를 자동적으로 측정하는 방법도 제시했다.
Architecture

- 가우시안 노이즈 z를 바로 이미지 생성에 사용하지 않고, 8층의 MLP를 거쳐서 생성된 intermediate latent space의 w 벡터를 사용한다.
- w 벡터는 learned affine network를 거쳐서 adaptive instance normalization의 scale과 shift를 조절한다. 이 과정에서 style이 입혀진다.
- Single channel image인 noise는 learned per-channel scaling network를 거쳐서 feature map에 더해진다. 이 과정에서 stochastic variation이 입혀진다.
AdaIN

w 벡터는 affine network를 거쳐서 위와 같은 tuple을 만들게 된다. 논문에서는 이 tuple을 style이라고 정의한다. 이와 같은 tuple이 각 layer마다 하나씩 만들어지고, 각 레이어에서 개별적으로 AdaIN을 조절하여 style을 입히게 된다.

어떤 layer의 i 번째 feature map에 대한 식은 위와 같다. 각 feature map은 모두 개별적으로 normalize, scale, bias 되므로 y의 dimensionality는 feature map 수의 2배가 된다.
어떤 이미지의 feature map들은 서로 평균과 분산이 다를 것이다. 각 feature map들은 이미지의 feature들을 추출해서 가지고 있다. 가령, 어떤 feature map은 이미지의 curved edge들을 가지고 있고, 어떤 feature들은 색 정보를 가지고 있다. 이런 다양한 feature들이 하나의 이미지를 나타낼 때, 어떤 feature가 강조되고 어떤 feature가 상대적으로 무시되는지를 그 이미지의 style이라고 생각할 수 있다. 만약 색 정보를 가지고 있는 feature map의 평균과 분산을 키운다면 그 이미지의 색감이 더 강해질 것이다. AdaIN에서는 우선 각 feature map을 normalize하고, w 벡터가 평균과 분산을 조절함으로써 style을 입힌다.
Quality of Images
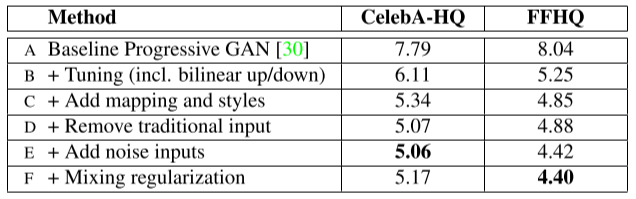
- B는 progressive GAN에서 bilinear up/down sampling, hyperparameter tuning, longer training으로 성능을 높인 버전이다.
- C에서 intermediate latent space를 만들고 style-based로 전환하였다.
- 그러고 난 뒤에, D에서는 더이상 synthesis network의 input으로 random variable을 주지 않아도 된다는 것을 발견하였다. 대신 learned constant가 input으로 들어간다.
- E에서는 noise를 추가하였다.
- F에서는 mixing regularization을 추가하였다.
Style mixing
이런 style-based generator architecture에서, style은 각 layer에 localize되는 속성을 가지고 있다. 그도 그럴 것이, AdaIN을 보면 매 layer마다 normalize를 하고 다시 새로 style을 입힌다. 이 논문에서는 generator를 잘 이해하고 컨트롤하고 싶기 때문에, 이런 속성을 더 강화시키고 싶다. 이를 위해 mixing regularization을 사용했다.
Mixing regularization이란, intermediate latent space에서 두 벡터 w1, w2를 뽑고, 어떤 random한 crossover point까지는 w1의 style을, 그 이후로는 w2의 style을 입혀서 이미지를 생성하는 방법이다. 만약 모델이 각 layer의 style간의 correlation을 이용해서 이미지를 합성한다면, w1과 w2가 교차되는 지점에서 실패할 것이다. 따라서 이 방법은 style의 localizing을 강화한다.

Mixing regularization을 0%, 50%, 90%, 100%의 비율로 사용했을 때의 결과물이다. 최대 4개까지의 mixing에도 robust한 성능을 보여주고 있다.

Style mixing은 이런 mixing regularization의 부산물인데, 매우 흥미로운 결과를 보여준다.
- 저해상도 단계에서 B의 style을 사용하고 그 이후로 A의 style을 사용하여 생성한 결과를 보면 포즈나 표정, 안경 등의 큼지막한 attribute는 B의 것을 따르고, 머리나 피부색 등의 detail한 attribute는 A의 것을 따르고 있다.
- 고해상도 단계에서 B의 style을 사용하여 생성한 결과를 보면, 이번에는 포즈나 표정은 A의 것을 따르고 detail한 attribute는 B의 것을 따르고 있다.
Stochastic variation
Stochastic variation은 이미지의 전체적인 style에 영향을 주지 않으면서도 무작위로 생성되는 모공, 잔머리 등을 말한다.

같은 환경에서 input noise만 바꾸었을 때, 이미지의 전체적인 윤곽은 변하지 않으면서 디테일만 변하는 것을 확인할 수 있다. (c)를 보면, noise는 옷의 질감, 머리카락 등에만 영향을 미치고 중요한 부분은 바꾸지 않는다.
이러한 stochastic variation을 생성하는 것은 기존 모델들의 어려운 점 중 하나였다. Stochastic variation은 realistic한 이미지를 만들어 discriminator를 기만하기 위해서는 반드시 필요한데, 무작위로 모공, 머릿결, 옷의 질감 등의 pseudo-random한 값들을 생성하는 것은 모델의 capacity를 소모하는 일이다. 심지어 capacity를 소모했음에도 불구하고 무작위로 생성하는 것에 실패하여, 기존의 모델이 생성한 이미지에서는 artifact들을 종종 관찰할 수 있었다.
이 논문에서는 매 layer마다 싱싱한 noise를 넣어주어서 모델이 stochastic variation을 생성하는 것을 도와주었다. 이는 style과 stochastic variation의 분리를 이끌어냈다. 만약 모델이 noise를 이용해 style을 입히려고 시도한다면 realistic한 이미지를 만드는 것에 실패할 것이다. Pixel별로 주어지는 random value로 style을 만든다면 일관성 없는 저품질의 이미지를 생성하게 될 것이기 때문이다. 즉, 모델은 noise를 이용해 stochastic variation을 만들고 latent vector를 이용해 style을 만드는 방향으로 unsupervised하게 학습할 것이다.

이러한 stochastic variation은 style과 마찬가지로 localize 되는 속성이 있다.
- (a)에서는 모든 레이어에 noise가 적용되었다.
- (b)에서는 noise가 적용되지 않았다. Stochastic variation이 없어서 이미지가 흐리고 부자연스럽다.
- (c)에서는 고해상도 레이어에서만 noise가 적용되었다. 왼쪽 사진을 보면 머리에 굵은 컬이 보이지 않는다. 오른쪽 사진을 보면, 남자 뒤의 배경에 구조물이 보이지 않고 자잘한 detail만 합성되었다.
- (d)에서는 저해상도 레이어에서만 noise가 적용되었다. 왼쪽 사진을 보면 머리에 디테일한 컬이 보이지 않는다. 오른쪽 사진을 보면, 남자 뒤의 배경에 구조물의 윤곽은 보이나 detail이 없다.
매 layer마다 noise가 외부에서 공급되므로, generator의 입장에서는 일찍부터 stochastic variation을 만들 이유가 없을 것이다. 따라서 이런 localizing이 발생하는 것이라고 추측할 수 있다.
Intermediate latent space

(a)는 training data distribution이다. 가로축을 남성성, 세로축을 머리 길이라고 했을 때, 머리 긴 남자라는 조합은 density가 매우 낮을 것이라고 예상할 수 있다. 이런 distribution을 학습하기 위해 generator는 z에서 image로의 mapping을 왜곡할 수 밖에 없다. 그렇지 않고서야 가우시안에서 무작위로 추출되는 z가 (높은 남성성, 긴 머리)라는 combination으로 가는 것을 어떻게 막을 수 있겠는가? (b)는 이런 상황을 잘 보여주고 있다. 이렇게 warp된 덕분에 entangle이 불가피하다. 하지만 (c)에서 보여주듯이, intermediate latent space는 어떤 고정된 분포(가령 가우시안 분포)를 따르지 않기 때문에 저런 모양이 가능하다. Generator는 (b)에서의 왜곡을 (c)와 같이 예쁘게 펴주는 방향으로 학습하게 되는데, disentangle이 잘 돼야 generator가 realistic한 이미지를 생성하기가 더 쉽기 때문이라고 논문에서는 주장하고 있다.
Perceptual path length

z1과 z2 사이의 어떤 t지점에서 생성된 이미지와 epsilon만큼 떨어진 지점에서 생성된 이미지 사이의 perceptual distance를 재서 expectation을 구한다는 아이디어이다. Distance로는 pre-trained VGG의 embedding간 거리를 사용했다. Normalize된 latent vector input에는 구형 보간을 사용하는 게 적절한 방법이기 때문에 slerp(spherical interpolation)를 사용하였다. Disentanglement가 잘 안되고 factor of variation이 잘 분리되지 않았다면 이 값이 높게 나올 것이다.

이 수식은 w를 위한 것이다. 유일한 차이점으로, w는 normalize 되지 않았기 때문에 선형 보간이 사용되었다.
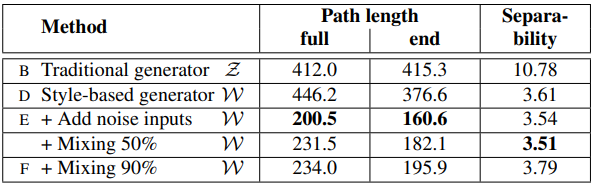
Noise가 추가된 style based generator가 훨씬 더 낮은 path length를 보여주고 있다. 위에서 본 그림 (c)의 뚫려있는 공간을 피하고자 w의 범위를 제한하면 path length는 더 줄어든다.
Linear separability
Disentangle이 잘 되었다면 각 구역이 image의 특정 binary attribute에 해당하도록 linear hyperplane으로 latent space를 분명히 구분할 수 있을 것이다. 예를 들어, 남자 이미지를 만드는 latent vector와 여자 이미지를 만드는 latent vector가 linear SVM에 의해 잘 구분된다면 disentangle이 잘 된 것이다. 우선, linear seperability를 측정하기 위해 linear SVM과 auxiliary classifier를 훈련시켰다.
Linear SVM -> X = 0, 1 (latent vector를 이진 분류한다)
Auxiliary classfier -> Y = 0, 1 (이미지를 이진 분류한다)
과 같이 binary classification을 하게 된다. 여기서 conditional cross entropy H(Y|X)를 구하고, 그것을 평균 내어서 linear seperability를 구한다.

Disentangle이 잘 되었다면 위와 같이 image의 class에 대응되게끔 latent space를 둘로 나눌 수 있을 것이다. 이 경우에는 latent space의 class를 알고 나면 image의 class는 거의 결정된다. 따라서 conditional cross entropy가 낮아진다.


Linear seperability가 높다 <=> Linear SVM으로 나눈 latent vector의 class가 그로부터 생성되는 이미지의 binary attribute를 잘 설명한다 <=> 따라서 X를 알 때, Y가 가지는 정보량(불확실성)이 적다.
이런 이유로 linear seperability를 conditional entropy로 측정하는 것이다.

Mapping network를 추가하는 것은 traditional GAN에서도 좋은 방법이다. Layer가 많아질 수록 성능이 좋아지는 경향이 있다.
Truncation trick in W

Training dataset에서 density가 낮은 data를 생성하면 퀄리티가 좋지 못하다. 모델이 몇 번 보지 못했을 것이기 때문이다. 여기서 약간의 variation을 포기하는 대신 그런 이미지를 애초에 생성하지 못하게 해서 퀄리티를 올리는게 truncation trick이다. 무작위 추출한 w 벡터를 평균에서 뺀 뒤에, 그 편차를 1보다 작은 값을 곱해 깎아서 사용한다.
'논문 리뷰' 카테고리의 다른 글
| Understanding Deep Learning Requires Rethinking Generalization (0) | 2021.02.06 |
|---|---|
| Training GANs with Limited Data (0) | 2021.01.23 |
| Few-shot Knowledge Transfer for Fine-grained Cartoon Face Generation (0) | 2021.01.12 |
| U-GAT-IT 리뷰 (0) | 2021.01.09 |
| VDSR 리뷰 (0) | 2021.01.02 |



