- Submission : 2020
- Paper Link : arxiv.org/abs/2006.06676
Keywords
- Data efficient GAN training
- ADA(Adaptive Discriminator Augmentation)
- Non-leaking augmentation
- Discriminator overfitting
Contribution
- ADA라는 augmentation 방법 제시, 10배 적은 데이터로도 styleGAN2와 대등한 성능을 보임.
- 적은 양의 데이터로 GAN을 학습시키는 다양한 방법들을 비교, 분석하고 최적의 방법 제시함.
Introduction
- Modern GAN에서 좋은 결과를 얻으려면 100K~1000K의 데이터가 필요함.
- 데이터가 적으면 discriminator overfitting이 일어나서 generator가 유의미한 feedback을 받지 못함.
- 기존의 data augmentation은 leaking 때문에 GAN에 적용할 수 없음.

- Figure (a)를 보면, 데이터 수와 성능은 매우 밀접한 관계를 가지고 있음. 적은 데이터에서는 training이 diverge함.
- Figure (b)와 (c)를 보면, discriminator output으로 discriminator overfitting이 일어나는 것을 확인할 수 있음.
- Discriminator가 적은 수의 training data에 overfit되어서 overlap이 없어지면 FID도 하락함을 알 수 있음.
Discriminator overfitting이 일어나면, discriminator가 강한 확신을 가지고 training data를 분류하게 되어 output의 절대값이 올라가게 된다. Discriminator는 training data의 지엽적인 특징에만 fire 되도록 overfit 되었기 때문에 validation set이 들어오면 fire되지 않고 가짜라고 판단하게 된다.
Designing augmentations that do not leak
만약 training data에 90도 회전이라는 augmentation을 주면, generator는 90도 돌아간 이미지를 생성한다. 이것을 leaking이라고 한다. Discriminator가 augmentation된 이미지와 그렇지 않은 이미지를 구분하지 못하게 되는 것이다. Non-leaking augmentation을 위해서는 우리가 이미지에 transformation을 가하되, 그 transformation이 확률 분포의 관점에서 invertible해야 한다. Invertible한 augmentation을 가했을 경우 training 과정에서 모델이 corruption을 걸러내고 원래의 분포를 잘 학습하게 된다고 한다. 자세한 이유는 AmbientGAN 논문을 살펴보자.
가령 전체 이미지의 90%를 0으로 만드는 변환을 한다고 하자. 그러면 90%의 검은 이미지를 제외하고 10%의 진짜 이미지를 찾을 수 있고, 그 augmentation을 undo 할 수 있다. 이것은 확률 분포의 관점에서 invertible한 변환의 예이다. 이번에는 {0, 90, 180, 270}도 중 무작위로 골라 이미지를 회전하는 augmentation을 생각해보자. 그러면 원래의 방향을 가늠할 수 없으므로 undo할 수 없고, 따라서 invertible하지 않다. 이런 augmentation에서는 leaking이 발생하게 된다.
여기서, augmentation을 p의 확률로 적용한다고 하자. 그러면 회전되지 않은 이미지의 개수가 늘어나므로 진짜 이미지를 구분할 수 있고, invertible하게 된다. 다시 말해, 어떤 augmentation이 p 값에 따라 leaking 할 수도 있고 non-leaking 할 수도 있다는 뜻이다.

- Figure (a)에서는 bCR이라는 방법을 소개하고 있다. Augmentation을 discriminator를 학습할 때에만 가하고, augmentation 전과 후의 이미지의 output의 consistency를 요구한다.
- Figure (b)는 이 논문이 소개하는 방식이다. G와 D를 학습할 때에 모두 augmentation을 가하고, augmentation된 이미지만을 D에게 보여준다.
- Figure (c)를 보면 p값이 올라갈수록 augmentation에 leaking이 일어남을 알 수 있다.


- Augmentation 방식에 따라 leaking하기 시작하는 p값이 모두 다르다.
- Data 수에 따라 각 augmentation의 효과가 다르다. 140k에서는 모든 augmentation이 해롭다.
- 모든 상황을 고려해서 최적의 p값을 찾아내는 것은 비용이 많이 든다.
- 설령 grid search로 최적의 p값을 찾았다고 해도, training 시점마다 최적의 p값은 다를 것이다.
Adaptive discriminator augmentation
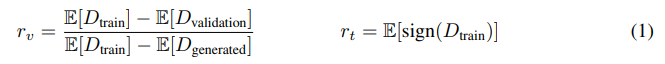
논문에서 제시한 discriminator의 heuristic이다. 왼쪽은 단지 비교를 위한 수식이고, 실제로 대부분의 실험에서 오른쪽을 사용하였다. 왼쪽의 수식은 validation set을 필요로 하기 때문에 limited dataset에서 적용하기 힘든 부분이 있다. 둘 다 0~1의 범위에서 1이면 discriminator overfitting이 매우 심한 것이고 0이면 전혀 없는 것이다. Overfitting이 심해질수록 discriminator가 validation set을 generated image라고 판단한다는 것을 위에서 확인했다. 이 경우 r_v는 1이 된다. r_t에서 sign이 붙은 이유는 단지 그렇게 하면 여러 세팅에서 덜 sensitive하기 때문이다.
이러한 heuristic의 target value를 0~1 사이의 임의의 값으로 정하고, 그 값을 기준으로 p값을 adaptive하게 조절하는 것을 ADA라고 한다.

- (b)를 보면, target value에 따른 성능 변화를 확인할 수 있다. 또한, 데이터 수가 적을수록 최적의 p값이 높아지는 것을 알 수 있다. 즉, 적은 데이터에서는 hard한 augmentation이 성능이 좋다.
- (c)를 보면, ADA를 사용했을 때 p값이 iteration이 올라감에 따라 점진적으로 올라간다. 초반에는 overfitting이 없기 때문에 낮은 p값을 가지다가, overfitting이 일어나려고 할 때 p를 높여서 막는 것이라고 해석할 수 있다.
- (d)를 보면, ADA를 사용했을 경우가 그렇지 않은 경우에 비해 overfitting heuristic이 일정한 값을 잘 유지하는 것을 확인할 수 있다.

ADA의 효과를 분석한 figure인데,
- (a)를 보면, 적은 수의 데이터로도 잘 수렴시키는 것을 확인할 수 있다.
- (b)를 보면, diverge하지 않고 overlap이 잘 유지됨을 알 수 있다.
- (c)는 generator가 discriminator로부터 받은 gradient의 magnitude를 시각화 한 것이다. Discriminator overfitting이 일어났을 때 generator가 뭉뚱그려진 feedback을 받는 반면, ADA를 사용했을 때 세밀한 feedback을 받는다.
Training from scratch

ADA에 bCR을 추가하면 성능이 향상된다. bCR은 leaking을 해결하지 못하기 때문에 단독으로 사용하면 성능이 나쁘다. ADA와 baseline의 성능 차이는 엄청나다. 1k일 때 fid가 80가량 차이나는 모습을 보여준다.
Transfer learning

- (a), (b)를 보면, transfer learning 시에 freezeD만으로는 overfitting이 잡히지 않고, ADA를 같이 써야 함을 알 수 있다.
- (c)를 보면, 데이터가 적을 때 ADA와 transfer learning을 같이 쓰면 엄청난 성능 향상을 볼 수 있다. 적어도 둘 중 하나의 방법은 반드시 사용해야 할 것이다.
Transfer learning시에, 두 데이터의 유사성도 중요하지만, pre-train에서의 데이터의 diversity가 중요하다. 가령, LSUN Cat으로의 transfer learning에서 CelebA-HQ보다 diverse한 FFHQ가 성능이 더 좋았다. 또한, FFHQ로의 transfer learning에서 LSUN Dog이 CelebA-HQ와 비슷하거나 좋은 성능을 보였다. FFHQ는 사람 얼굴 데이터셋이지만, LSUN Dog의 diversity가 높으므로 transfer가 잘 된 것이다.


데이터가 2k 미만일 때 transfer learning과 ADA의 효과는 매우 강력하다. (a)에서 제시하는 transfer learning의 결과는 FFHQ에서 pre-train 한 것이다. 얼굴 데이터셋에서 pre-train된 모델이 의료 이미지 생성으로 transfer learning이 가능한 것을 볼 때, 두 subject의 동일성도 중요하지만 pre-train된 데이터의 diversity가 중요함을 다시 한 번 알 수 있다. Transfer learning + FreezeD + ADA가 전반적으로 가장 좋은 결과를 보였다. 여기서는 KID가 쓰였는데, 데이터가 20k 미만인 경우에 FID의 bias가 심하기 때문이다.

이 그래프의 붉은 점선은 training data 개수에 따른 FID의 bias를 나타낸 것이다. Training dataset의 subset을 뽑아 training dataset과의 FID를 100번 재서 average 한 것인데, 같은 distribution이므로 FID는 0이 나와야 하지만, 데이터가 1k개일 때를 보면 FID가 20 이상이 나온다. 데이터 수가 적을 때 FID는 거의 사용이 불가능함을 알 수 있다.
Conclusion
ADA, transfer learning, freezeD를 이용해서 limited data에서도 GAN을 잘 훈련할 수 있다. Metric은 FID보다 KID를 사용하자. 위에 열거한 어떤 기법도 실제 데이터를 대체할 수 없다. 가능하다면 데이터를 더 모으자.
'논문 리뷰' 카테고리의 다른 글
| A Style-Based Generator Architecture for Generative Adversarial Networks (0) | 2021.02.19 |
|---|---|
| Understanding Deep Learning Requires Rethinking Generalization (0) | 2021.02.06 |
| Few-shot Knowledge Transfer for Fine-grained Cartoon Face Generation (0) | 2021.01.12 |
| U-GAT-IT 리뷰 (0) | 2021.01.09 |
| VDSR 리뷰 (0) | 2021.01.02 |



