- Submission : 2017
- Conference : ICLR
- Paper Link : arxiv.org/abs/1611.03530
Keywords
- Generalization
- Understanding deep learning
Contribution
- 현존하는 딥러닝 모델들의 일반화 성능을 지금의 이론으로 설명할 수 없음을 보임.
Introduction
현존하는 딥러닝 모델들은 training data 전체를 memorize 할 수 있을 만큼 parameter가 많다. 그럼에도 불구하고 generalize가 꽤 잘 된다. 즉, training과 test시에 성능 차이가 그렇게 크지는 않다. 물론, generalize를 못하는 모델도 있다. 잘되는 모델과 안되는 모델의 차이를 알면, 잘되는 모델을 만들 때 도움이 될 것이다. 하지만 이 논문에서는 지금까지의 이론으로는 그것이 불가능함을 보인다.
Random label experiment

CIFAR-10 classification 문제를 푼다고 하자.
- True label : 일반적인 classification 상황.
- Shuffled pixels : Dataset의 각 image들의 픽셀을 shuffle 함. 단, 각 이미지에 대해 모두 같은 방식으로 shuffle함.
- Random pixels : Shuffled pixels와 달리, 각 이미지에 대해 모두 다른 방식으로 shuffle함.
- Gaussian : 원래 이미지의 mean과 std를 따르는 gaussian 분포에서 random pixel을 뽑아 각 이미지를 다시 생성함.
- Random labels : 이미지는 그대로 두고 label을 shuffle함. 이 경우 data와 label간의 연관성이 아예 사라지게 됨.
1에서 5로 갈수록 모델이 fitting 하기 더 어려워진다(3과 4는 비슷하다).
신기한 것은, data와 label간의 아무런 correlation이 없어도 모델이 잘 overfit 한다는 것이다. 즉, 모든 모델이 다 random label을 fit할 만큼의 complexity를 가지고 있기 때문에 지금까지의 complexity measure로는 왜 어떤 모델은 generalize가 잘 되고 어떤 모델은 잘 안되는지 설명이 불가능해진것이다.
(c)를 보면, label corruption rate가 올라갈수록 서서히 모델의 일반화 능력이 떨어지는 것을 볼 수 있다. 이는 모델이 학습 시에 noise와 signal을 구분한다는 것을 보여준다. 여기서도 마찬가지로, corruption rate에 따라 일반화 성능은 떨어질지언정 training error는 모든 경우에 다 0을 달성할 수 있음을 확인할 수 있다.
결론 : 현존하는 모델들의 effective capacity는 데이터 전체를 외울 만큼 크다.
Previous complexity measurements
Rademacher complexity

기존에 hypothesis class의 complexity를 측정하기 위해 사용하던 방법이다.
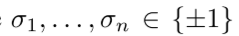
시그마는 uniform probability로 -1이나 1중 하나이다. 데이터 {x1, x2, ... , xn}을 받아서 h에 넣은 output이 랜덤한 variable 시그마와 곱한 값이 최대가 되게 한다고 하자. 여기서는 binary classification 문제라고 생각하면 된다. 모델 입장에서는 -1과 곱해져서 최대가 되려면 -1을, 1과 곱해져서 최대가 되려면 1을 뱉으면 되는데, 문제는 시그마가 random variable이므로, 마치 위에서 봤던 random label experiment와 비슷한 setup이 된다. Rademacher complexity가 1이라는 것은 모델이 위와 같은 random한 setup에서도 잘 fitting 했다는 것이므로, complexity가 크고 따라서 generalize를 잘 못할 것이라고 이야기 할 수 있다는 개념이다.
문제는 위에서 실험한 대로 현존하는 딥러닝 모델들은 random label도 잘 fit한다. 즉, rademacher complexity는 거의 항상 1이 나올 것이다. 따라서 이 방법으로는 일반화 능력을 판단할 수 없다.
Uniform stability
이 방법은 어떤 알고리즘이 input의 변화에 얼만큼 sensitive한가를 지표로 그 알고리즘의 일반화 능력을 판단한다. 문제는 이 uniform stability는 어떤 알고리즘에 대한 속성이므로, data나 label 등은 고려하지 않는다는 것이다. 위의 figure에서 확인했듯이 label corruption rate에 따라 일반화 성능은 달라진다. Uniform stability는 어떤 모델에 대해 일정한 값이므로 data와 label에 따라 하나의 모델의 일반화 성능이 달라지는 것을 설명하지 못한다.
The role of regularization

Regularization은 일반화 성능을 올려주긴 하지만, regularization 없어도 잘 된다. 따라서 이 또한 왜 일반화가 잘 되는가에 대한 설명이 아니다.
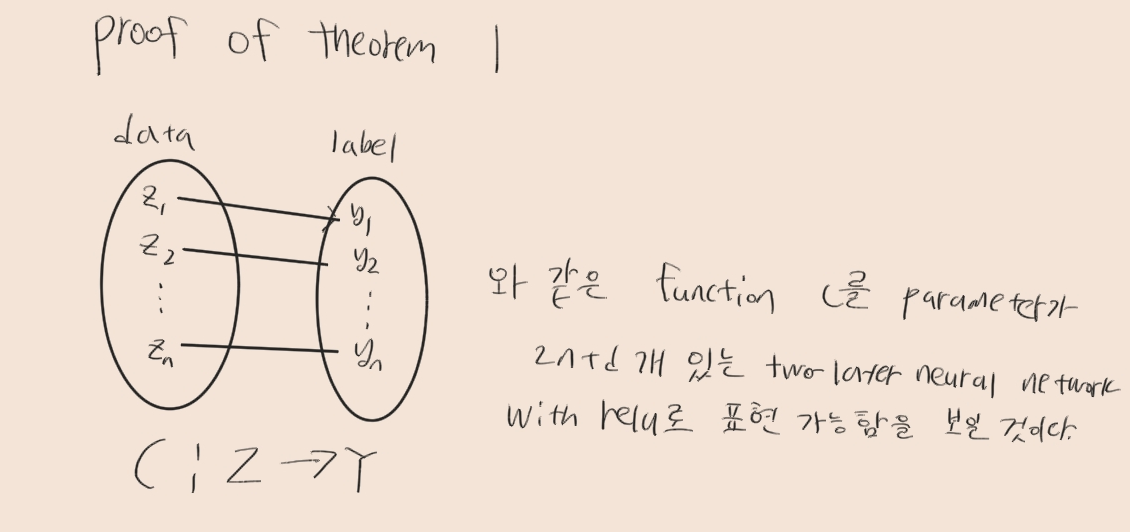
Expressivity of neural network
n x d의 shape을 가진 데이터에 대한 모든 function은 2n+d개의 parameter를 가지는 two-layer neural network with relu로 표현될 수 있다는 것을 증명하였다.




Conclusion
- 2n + d개의 parameter를 가진 two layer NN만으로도 데이터에 대한 모든 함수를 표현할 수 있다.
- 현존하는 모델들의 effective capacity는 random label을 fitting 할 만큼 충분히 크다.
- 기존의 statistical learning에서 제시한 complexity measurement들도 의미가 없다.
- Regularization도 충분한 설명이 되지 못한다.
분명히 일반화를 잘 하는 모델과 그렇지 않은 모델의 차이는 있을텐데, 지금으로서는 알 수가 없다. 딥러닝은 왜 잘 되는걸까? 추가적인 연구가 필요하다.
'논문 리뷰' 카테고리의 다른 글
| A Style-Based Generator Architecture for Generative Adversarial Networks (0) | 2021.02.19 |
|---|---|
| Training GANs with Limited Data (0) | 2021.01.23 |
| Few-shot Knowledge Transfer for Fine-grained Cartoon Face Generation (0) | 2021.01.12 |
| U-GAT-IT 리뷰 (0) | 2021.01.09 |
| VDSR 리뷰 (0) | 2021.01.02 |



