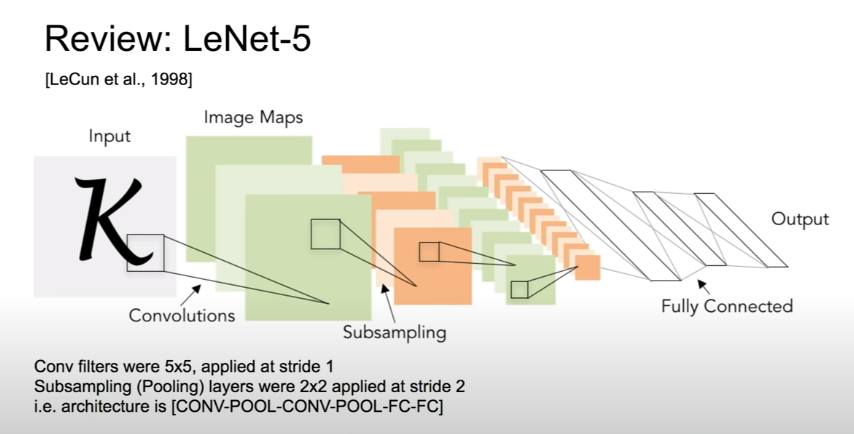
ConvNet을 실제로 적용해서 거의 처음 좋은 결과를 얻었던 LeCun의 LeNet이다.

AlexNet의 첫 layer의 output size와 parameter 수는 몇 개일까? 다시 한번 풀어보자.

AlexNet이 사용한 방법들. 추가적으로, 모델을 vram에 올리기 위해 반으로 쪼갰다. Feature map이 절반으로 쪼개져서, 같은 gpu에 없는 feature map은 보지 못한 채로 연산된다. 마지막에 fcn을 거치면서 서로 다른 gpu간의 정보 공유가 이루어진다. ZFNet이 AlexNet의 hyperparameter를 만져서 다음 해에 imageNet에서 우승했다.

2014년에 등장한 VGG는 backbone 모델로 많이 쓰인다. 3x3의 작은 필터를 깊게 쌓았다.
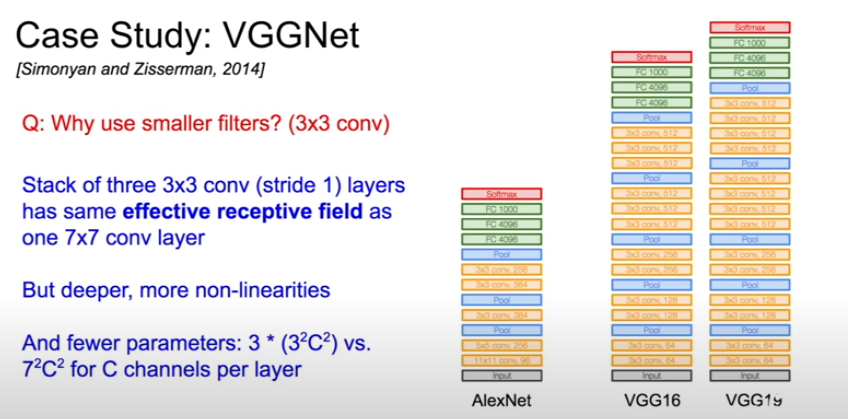
왜 그랬을까? 3x3 필터를 3겹 쌓으면 7x7 필터 하나와 receptive field가 같아지면서, non-linearity도 증가하고(depth가 깊어졌으니까) parameter 수도 줄일 수 있다.

7x7의 이미지는 2번의 3x3 필터와의 convolution 연산을 거쳐서 3x3의 feature map이 된다. 세 번째 3x3 filter는 전체 이미지의 feature map을 한 눈에 본다. 3겹의 3x3, stride 1의 filter의 receptive field가 7x7이라는 것은 이런 의미이다.

138M개의 파라미터를 가지고 있고, 이미지 하나 당 100mb를 먹는 엄청 무거운 모델임을 알 수 있다. 여기서 파라미터는 138M개인데 메모리는 왜 24M에 4를 곱해서 구하는지 궁금할 수도 있다. 정리하자면, 모델이 잡아먹는 메모리를 구할 때는 파라미터 수로 구하는게 아니고, feature map의 용량을 더해서 구한다. 물론 파라미터도 메모리에 올라가긴 하지만 모든 input에 대해 같은 파라미터를 쓸 것이기 때문에 하나만 존재하면 되고, 즉 138M x 4라고 해봐야 별로 크지 않다. 하지만 feature map은 각 input마다 하나 씩 있는 것이기 때문에 문제가 된다. 저기서 24M x 4 bytes는 feature map의 사이즈를 구하는 것이라고 보면 된다.
이 VGG는 16층짜리와 19층짜리가 있는데, 19층짜리는 메모리랑 계산을 더 요구하고, 성능이 그렇게까지 좋아지지는 않는다.

GoogLeNet은 depth를 높이면서도 효율성을 챙긴 모델이다. 저 inception module을 계속 쌓아 나간 구조이고, auxiliary classifier를 중간에 두 개 달아서, 총 3개의 classifier의 output을 평균 내어 훈련에 사용했다. 네트워크가 깊으니까 이렇게 해서 gradient vanishing을 막아보려고 했던 것 같다. 이런 방식은 중간에 뽑은 feature map으로도 classification이 잘 되어야 한다고 모델에게 요구하는 것이라고 할 수 있다. 그러면 이미 잘 되는 feature map을 가지고 레이어에 더 태웠으니까 당연히 마지막 layer에서도 잘 되어야 한다는 intuition도 있지 않을까?

Inception module은 여러 종류의 convolution 연산을 한 후 각 feature map들을 zero-padding 등으로 사이즈를 맞춘 다음 depth-wise하게 쌓아서 내보내는데, 이 과정에서 계산 복잡도를 줄이기 위해 1x1 conv 연산으로 depth를 줄이는, projection을 추가했다. 그리고 마지막 layer에서 fcn을 없앴기 때문에 파라미터 수가 전체적으로 많이 감소했다.
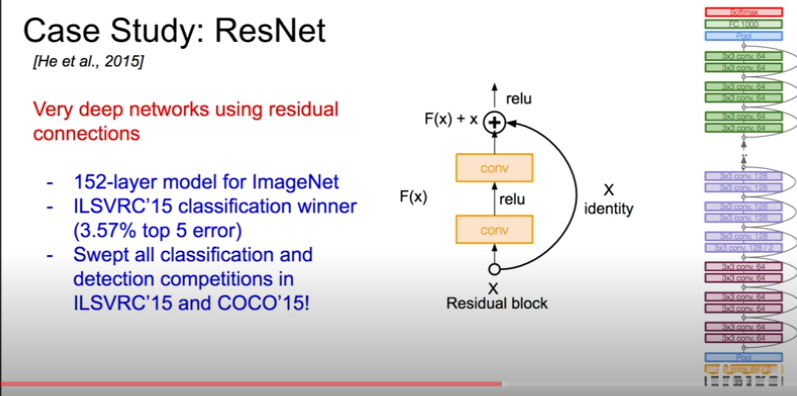
ResNet은 152층의 엄청나게 깊은 구조에 skip connection을 도입해서 좋은 결과를 냈다.

ResNet 저자가 cnn을 depth를 높여가면서 실험을 했는데, 위와 같은 결과가 나왔다. Depth를 높이면 네트워크의 표현력이 올라가니까 좋은 결과가 나올 것 같다. 현실적으로는 불필요하게 많은 파라미터 수는 계산 복잡도를 증가시키는 것은 물론이고 overfitting을 유발해서 test error가 오히려 올라가게 된다. ResNet 저자의 생각은, 여기까지는 상식적으로 이해가 되는데, 대체 왜 training error도 올라가냐는 것이다. 더 많은 파라미터로 더 많은 표현력을 얻었으면 그걸 이용해서 적어도 overfitting 정도는 할 수 있어야 하는데, depth가 쌓이면 쌓일수록 그 조차 안된다는 것이다. 즉, 문제는 overfitting이 아니고 optimization을 잘못한 것이다.
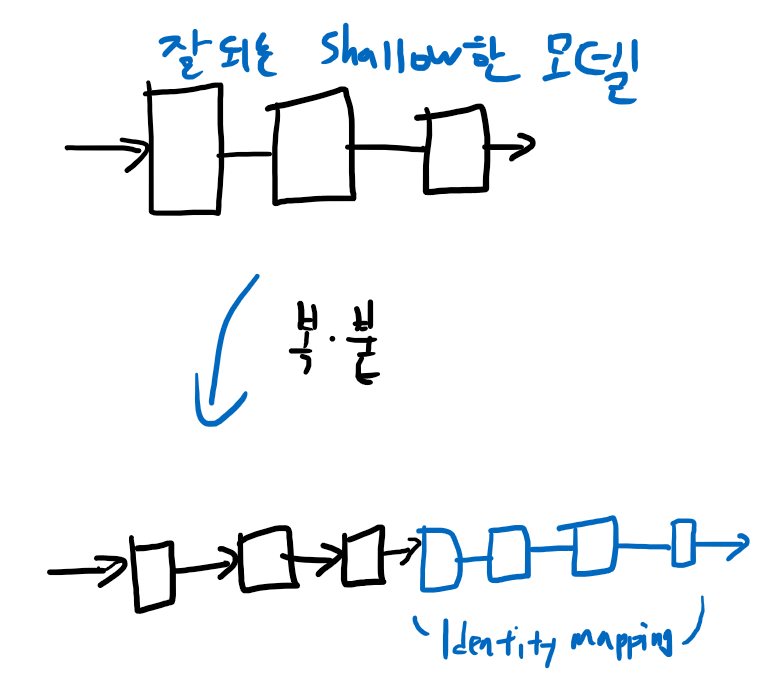
이렇게만 학습해도 최소한 shallow 모델 만큼의 성능은 나와야 한다. 이런 생각에서 착안해서 만든게 skip connection이다.
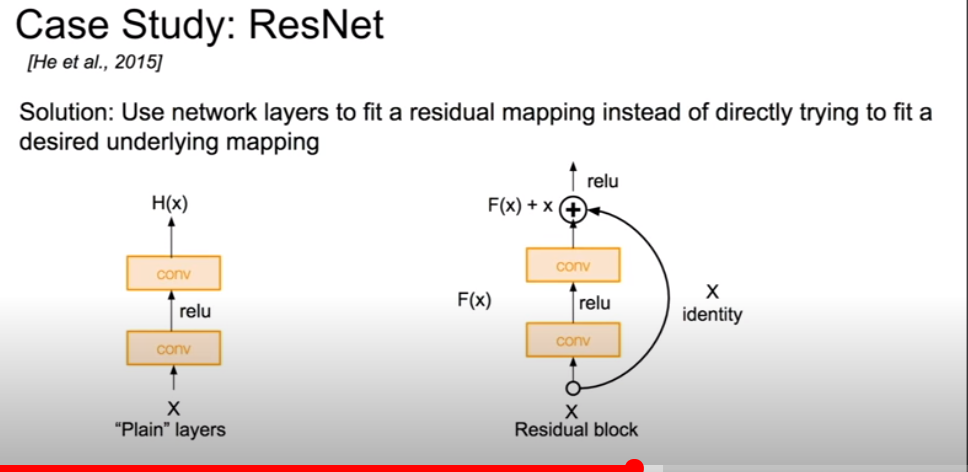
Shallow한 layer들도 잘 한다면, 그 output feature map에서 residual한 부분만 추가해서 만들면 최소한 성능이 떨어지지는 않지 않겠는가?(여기서 input x는 이전 layer의 output feature map이다) 물론 이건 증명된 게 아니고 ResNet 저자의 intuition일 뿐이다. ResNet에 challenging하는 논문들도 많이 나왔다.
즉, 우리가 바라는 이상적인 feature map인 H(x)가 있다고 할 때, 이걸 처음부터 만드는 건 어렵고 그래서 지금까지 depth가 늘어나면 실패했던 것이다. 그런데 input feature map인 x가 어느정도 H(x)랑 비슷할 테니까 skip connection을 넣어서, 그러면 H(x) = F(x) + x니까, 우리는 F(x)가 H(x) - x가 되도록 학습하면 된다. 이것을 residual learning이라고 한다.
마찬가지로 마지막 fcn을 없애고, global average pooling을 썼다. 50층 이상의 모델에는 위의 GoogLeNet처럼 projection을 써서(1x1 conv) 연산량을 줄였다.
이 모델부터 image classification을 사람보다 잘 하게 된다. Andrej Karpathy가 엄청 열심히 연습했는데 ResNet에게 졌다고 한다(ㅋㅋㅋ).

모델들의 Top 1 accuracy와 computational cost를 확인해보자. VGG는 파라미터도 많고, 메모리도 많이 먹고, 성능도 그저 그렇다.
그 뒤에도 NiN, 다양한 ResNet의 변종들, DenseNet등을 배웠다.

GoogLeNet이나 ResNet처럼 1x1 conv 연산으로 input depth를 줄이고, expand하는 구조로 SqueezeNet은 AlexNet의 파라미터를 500배 정도 줄이면서도 성능이 거의 비슷하다. Inception module과 구조적으로 유사해 보인다.
'수업 정리(개인용) > cs231n' 카테고리의 다른 글
| CS231n Lecture 11 : Detection and Segmentation (0) | 2021.01.06 |
|---|---|
| CS231n Lecture 10 : Recurrent Neural Networks (0) | 2020.12.31 |
| CS231n 2017 Lecture 8 : Deep Learning Software (0) | 2020.12.26 |
| CS231n 2017 Lecture 7 : Training Neural Networks II (0) | 2020.10.04 |
| CS231n 2017 Lecture 6 : Training Neural Networks I (0) | 2020.10.03 |



