Lecture 리뷰를 먼저 써야 순서가 맞는데, 과제를 너무 재미있게 해서 과제 리뷰부터 하기로 했습니다.
첫번째 과제는 Lecture2에서 배운 KNN입니다. KNN에 대한 설명은 나중에 Lecture2 리뷰에서 다루도록 하겠습니다.
강의는 유튜브에 있는 2017년 버전을 듣지만 과제는 2020년껄 할 수 밖에 없습니다. 전 년도 과제들은 사이트를 닫았더군요. cs231n.github.io/에 가시면 과제를 보실 수 있습니다.

뭔가를 해야 하는 부분은 여기부터죠. 주석에 써 있는 경로에 가서 .py 파일을 idle로 연 뒤 주피터랑 같이 보면서 하면 편합니다. compute_distances_two_loops를 구현하라고 하죠. Two_loops 버전은 쉽습니다. 이중 for문을 돌려서 하면 되니까요. 이후에 one_loop랑 no_loops도 나오는데, 결국 dist(i,j) = L2_distance(x_test[i], x_train[i])인 행렬 dist를 구하는 메서드인건 같습니다. Loop 수를 줄여서 빠르게 만들라는거죠.
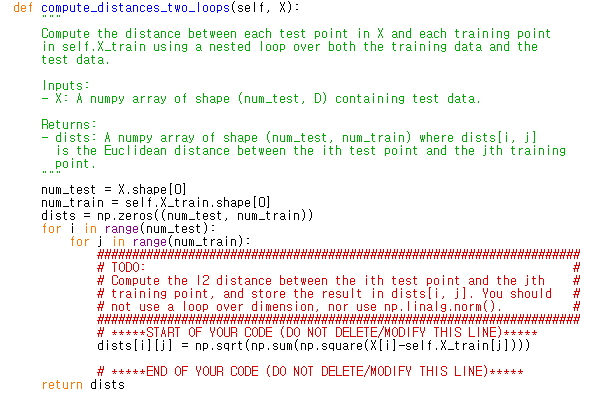
이게 제 two_loops 코드입니다. 여긴 별로 얘기할 게 없네요.
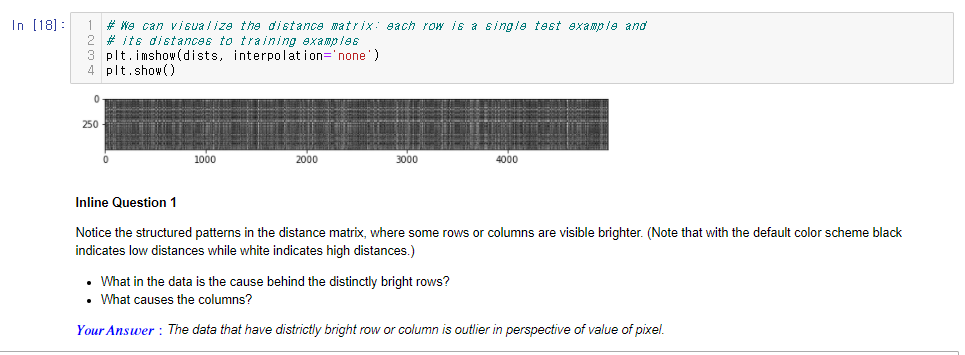
Inline Q1입니다. 이런 중간중간에 퀴즈 있는게 참 재밌는 것 같아요. 저 그림에서 세로축이 test data고 가로축이 train data이고, 색이 밝을수록 L2 distance가 큽니다. 가로에 밝은 선이 의미하는건 어떤 test data가 모든 train data와 L2 거리가 멀다는 의미죠. 세로 선은 반대로 어떤 train data가 모든 test data와 거리가 멀다는 것이구요. 따라서 이 데이터들은 픽셀 값의 관점에서 봤을때 아웃라이어라고 생각했습니다. 다른 이미지들보다 밝기가 엄청 밝거나, 혹은 엄청 어둡거나 하는 식으로 값이 픽셀 값이 많이 차이가 날겁니다. 혹시 틀렸다면 댓글로 알려주시면 감사하겠습니다.

Inline Q2입니다. 해석을 하자면 μ는 모든 이미지의 픽셀값의 평균이고, μ ij는 모든 이미지의 (i,j) 픽셀값의 평균이라네요. σ는 모든 이미지 픽셀값의 표준 편차이고, σij는 모든 이미지의 (i,j) 픽셀값의 표준 편차이군요.
1. L1 거리는 두 벡터의 차이의 합입니다. 예를 들면 (1,2,3)과 (4,5,6)의 L1거리를 구하려면 두 개의 차이를 구하기 위해 뺀 후 절대값을 취하게 되죠. (l-3l, l-3l, l-3l)처럼요. 그런데 양 벡터에서 μ를 빼도 (1-μ, 2-μ, 3-μ) 와 (4-μ, 5-μ, 6-μ)를 뺄셈 계산 하면 -μ가 상쇄되어 버리죠. 다른 방식으로 설명할 수도 있는데, 모든 데이터에서 μ를 빼면 그냥 데이터 분포를 μ만큼 왼쪽으로 평행이동 한 것이기 때문에 L1 거리는 같을 수 밖에 없습니다.
2. 1번의 핵심은 같은 값을 빼기 때문에 상관이 없다는 것이었습니다. 그런데 μij는 i,j위치의 픽셀들의 평균이기 때문에 픽셀 위치마다 그 값이 다릅니다.
3. distance matrix를 구해놓고 그것을 양수로 나눈다고 합시다. 그래도 element간의 대소 관계는 변하지 않습니다. KNN은 distance끼리 값이 크고 작음을 비교해서 결과를 내는 방식이므로 영향이 전혀 없을 것입니다. 실제로 데이터를 저렇게 정규화해서 많이 쓴다고 합니다.
4. 문제 2번에서 이미 μij를 빼는 것은 classifier의 결과를 바꾼다고 했습니다. 그것을 std로 나누어준다고 상황은 변하지 않습니다. 심지어 std(i,j)도 i,j위치마다 값이 다릅니다.
5. L1 distance는 coordinate system에 따라 값이 달라진다고 lecture2에서 말했습니다. 예를 들어 그림으로 보자면

원점에서 빨간 4개의 점까지의 L1 거리는 같습니다. 하지만 하나의 선분을 θ만큼 회전 시키면 더이상 L1 길이가 같지 않습니다. 지금은 선분을 회전 시켰지만 좌표축을 회전 시켜도 L1거리가 달라질 것을 알 수 있습니다. 그러므로 모델의 성능에 영향을 끼칠 것입니다.
one_loop을 구현하라고 합니다. Numpy의 broadcasting을 이용하면 쉽게 생각해 낼 수 있습니다.
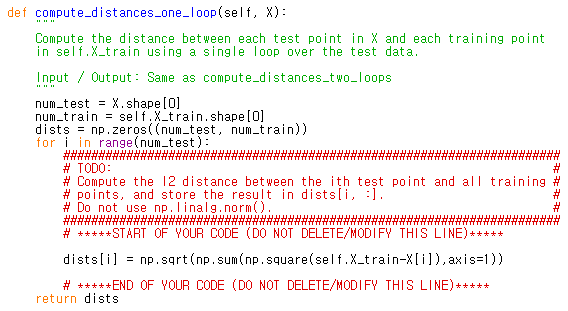
one_loop도 별로 얘기할 것이 없죠. 문제는 no_loops인데, 생각을 많이 해야 했습니다.


친절하게 힌트가 주어졌습니다. 처음에는 X를 3차원 배열로 reshape하고 broadcasting을 바로 적용해서 풀려고 했었는데, 어? 힌트에서는 행렬곱 쓰라고 했는데? 하다가 아니나 다를까, 메모리가 부족하다고 에러를 뱉었습니다. 이 문제를 풀려면 (a-b)(a-b)가 a*a + b*b - 2ab임을 떠올리는 데서 출발해야 합니다.

힘들게 구현한 no_loops가 압도적인 결과를 보여줍니다. 나눠보면 Two loop보다 150배가량 빠르네요. 신기한건 One loop가 Two loop보다 느립니다. 당황했었는데, 주석의 설명을 보니 정상이라고 하네요.
다음은 cross-validation입니다. Lecture2에서 배운대로 train data를 num_folds개로 쪼개서 각각의 fold를 한번씩 validation data로 써먹는 방법입니다. 소규모 데이터일때 그렇게 많이 한다고 합니다. 이 과정에서 우리의 hyperparameter들을 정해야 합니다.
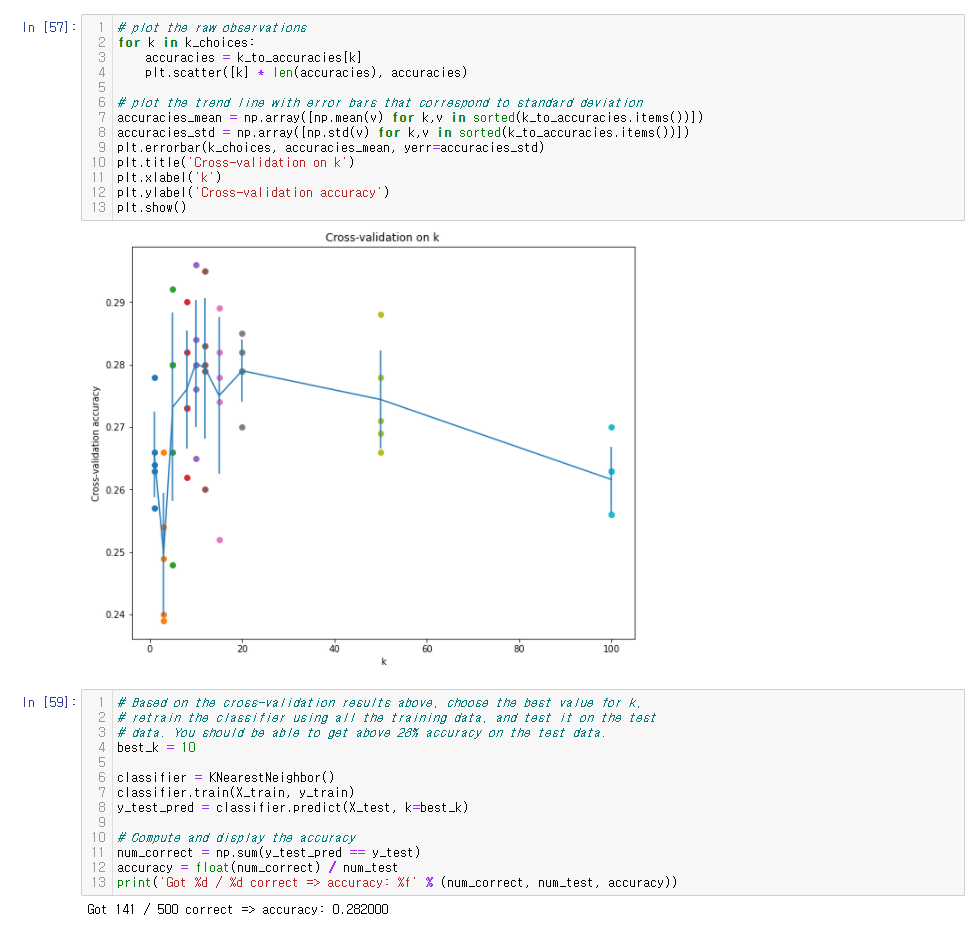
Cross-validation 결과 그래프입니다. K값의 후보로 10과 20을 선택했었는데, 처음엔 20을 골랐습니다. 왜냐하면 average는 미세하게 10이 좋지만 20이 표준편차가 낮은 stable한 결과를 보여줬기 때문입니다. 10이 굉장히 잘 할 수도 있지만 반대로 0.27가까이 떨어질 수도 있다고 생각했습니다. 하지만 결과는 10이 더 좋았습니다(ㅎㅎ..).

마지막 Inline Q3입니다.
1. Decision boundary는 label을 결정하는 그 기준선을 말하는 것인데, knn은 distance를 가지고 label을 결정합니다. 그래서 굉장히 들쑥날쑥한 모양을 가질 것입니다. 제가 떠올린 것은 Lecture2에서 보여주는 그림입니다.

2. k가 1이면 train 데이터가 들어왔을 때 이미 존재하는 자기 자신과의 거리가 0이므로 자기 자신의 label을 선택할 것입니다. 따라서 error가 0일 것입니다.
3. Lecture2에서도 웬만하면 K를 1보다 키우는 게 낫다는 이야기를 했었고, 이미 위의 그래프가 반례이므로 쉽게 선택했습니다. 물론 어떤 K가 좋냐는 케이스 바이 케이스일 것입니다.
4. 위에서 knn을 구현할 때 dist 행렬을 구했어야 했는데, dist의 shape이 (test_num, train_num)이었습니다. 따라서 train_num이 증가하면 필요한 연산량이 증가할 것입니다.
너무 즐겁고 생각을 많이 하게 했던 잘 짜여진 과제였던 것 같습니다. 문제들의 정답이 따로 나와있지 않아서 혹시 틀린 데가 있으면 지적 바랍니다.



