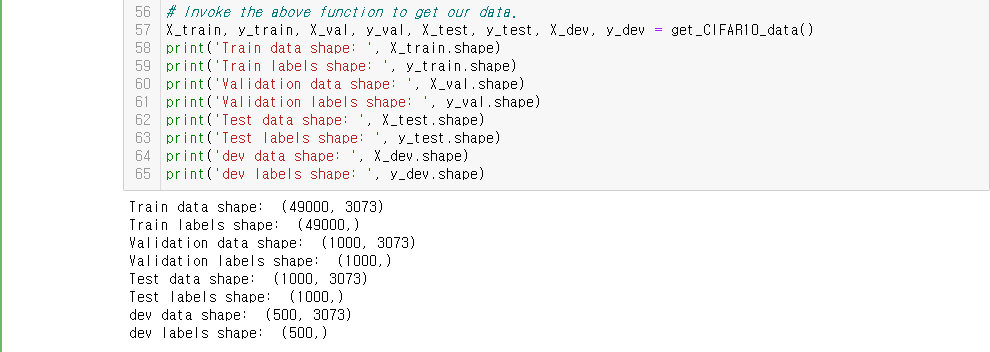
CIFAR-10 데이터를 이렇게 분할해서 사용할 것이다.

softmax.py에 들어가서 softmax_loss_nave를 구현한다.
Inline Q1.
W가 처음에 0에 가까운 값들로 초기화 되기 때문에, exp 연산을 거치면 score의 모든 값이 1이 되어 버린다. 따라서 softmax를 거친 값은 1/cls_num이고 CIFAR-10의 class 수는 10개 이므로 loss는 -log(1/10)이 된다.

Softmax의 computational graph는 위와 같고, 이 그래프를 차분히 해석하면 gradient를 구할 수 있다.

코드는 위와 같다. Regularization을 잊지 말자.

Numerical gradient와 비교해서 잘 짰는지 확인하자.

Naive 버전을 잘 짰다면 vectorized 버전은 크게 어렵지 않다. Log에 0.0001을 더해준 것은 log가 0으로 가서 inf값이 나오는 것을 방지하기 위함이다.
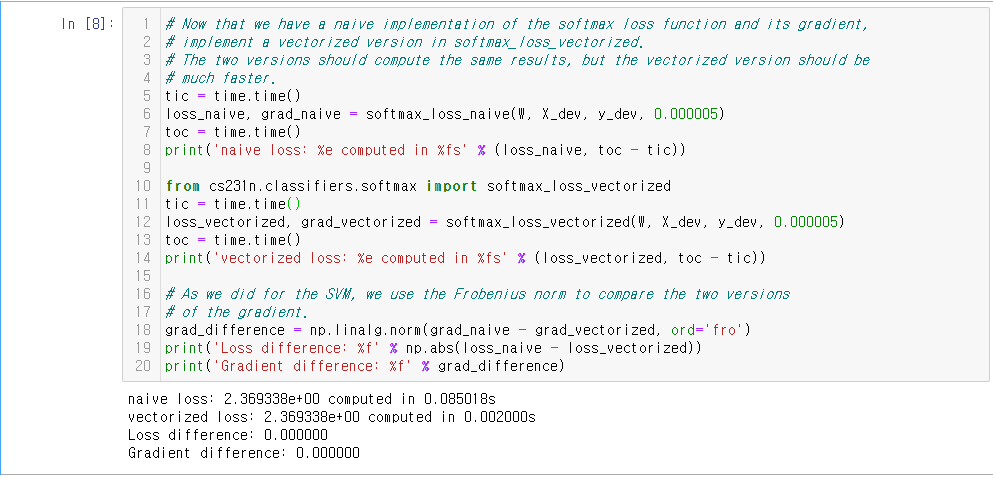
Vectorized 버전이 약 40배 이상 빠른 것을 볼 수 있다.

SVM 과제랑 비슷한 부분이다. Softmax 클래스를 import 해서 사용할 것이다.

Softmax 클래스는 찾아가보면 LinearClassifier를 상속하는데, 그 클래스에 SVM때 썼던 train이랑 predict 메소드가 있다. Learning rate와 regularization strength는 기본으로 주어진 값 이외에 몇가지 후보를 더 추가해서 테스트 해보았다.

Validation에서 0.35를 넘으라고 주어졌는데 0.394는 양호한 정확도인 것 같다.
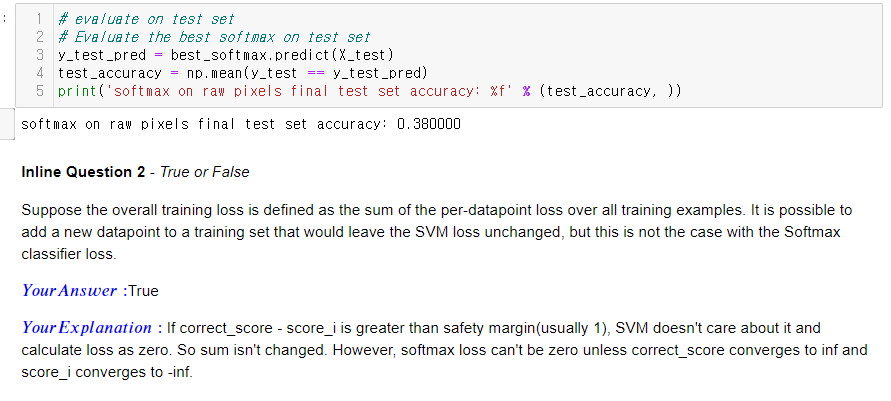
Test accuracy는 0.38이 나왔다. SVM에서 0.365가 나왔었는데, 큰 차이는 없어 보인다.
Inline Q2.
Loss를 training data 각각의 loss의 sum으로 정의할 때, 어떤 data를 추가하고 SVM_loss는 안변하지만 softmax_loss는 변하는 것이 가능하냐는 질문이다. SVM은 정답 스코어가 다른 스코어들보다 1(safety margin) 이상 높으면 loss를 다 0을 줘버리는 아주 후한 친구이다. 그러니까 그런 조건에 해당하는 data를 추가하면 그 data의 loss가 0이 나오기 때문에 sum이 변하지 않는다. 하지만 이전 lecture에서도 말했듯이 softmax는 loss가 0이 나올 일이 없다. Softmax라는게 exp를 거친 이후 각 score_exp가 차지하는 비율인데, 이게 1이 되려면 다른 값들이 다 0이 되어야 한다. 그런데 exp 값이 0에 도달하려면 score가 -inf로 수렴해야 한다.

W들을 visualize 한 것이다. Template이 모양이 흐릿해서 1000번 iter를 돌리며 학습을 더 시켰다. Acc는 0.388이 나왔다.
'수업 정리(개인용) > cs231n' 카테고리의 다른 글
| CS231N Spring 2020 Assignment1 : Features (0) | 2020.10.01 |
|---|---|
| CS231N Spring 2020 Assignment1 : Two Layer Net (0) | 2020.09.27 |
| CS231n 2017 Lecture 5 : Convolutional Neural Networks (0) | 2020.09.25 |
| CS231N Spring 2020 Assignment1 : SVM(Multiclass Support Vector Machine) (1) | 2020.09.20 |
| CS231n 2017 Lecture 4 : Introduction to Neural Networks (0) | 2020.09.19 |



