
leimao.github.io/blog/Batch-Normalization/
위 블로그에 아주 쉽게 정리가 되어있다. 다만 layer normalization은 틀리게 설명하고 있으므로 batch normalization만 보면 좋다.
Batch Normalization은 위와 같이 각 feature map별로 평균과 분산을 구한다. Feature map안의 location 정보는 사라진다(어차피 sum이므로 위치를 뒤바꿔도 같은 평균이 나올 것이다).

그런데 feature map은 여러 개이므로 한 batch에서 mean vector를 뽑으면 위와 같을 것이다.
이런 batch normalization은 몇 가지 단점이 있는데,
1. Batch 통계량을 사용하므로 하나의 batch가 모두 계산되기 전까지 다음 단계로 넘어갈 수 없다(sequential).
2. RNN에 적용하기가 까다롭다.
"When we apply batch normalization to an RNN in the obvious way, we need to to compute and store separate statistics for each time step in a sequence. This is problematic if a test sequence is longer than any of the training sequences."
Layer Normalization(2016)
- RNN에서는 각 timestep별로 통계량이 다를 것이므로 각각 가지고 있어야 하는데, 만약 test time에 training data에 없던 엄청 긴 sequence가 들어오면 BN을 적용할 수 없게 된다. 우리는 t번째 timestep까지의 평균과 분산을 가지고 있는데, 그러면 t+1번째부터는 어떻게 normalize 할 것인가?
3. Batchsize가 너무 작으면 사용할 수가 없다.

Layer normalization은 매우 단순한데, 그냥 하나의 데이터에서 나온 activation들을 다 합해서 mean을 구한다. 더이상 batch 통계량을 사용하지 않으므로 위에서 말한 단점들은 사라진다.
그런데 CNN에서의 적용은 조금 아리까리한 면이 있다.
Layer normalization offers a speedup over the baseline model without normalization, but batch normalization outperforms the other methods. With fully connected layers, all the hidden units in a layer tend to make similar contributions to the final prediction and re-centering and rescaling the summed inputs to a layer works well. However, the assumption of similar contributions is no longer true for convolutional neural networks. The large number of the hidden units whose receptive fields lie near the boundary of the image are rarely turned on and thus have very different statistics from the rest of the hidden units within the same layer. We think further research is needed to make layer normalization work well in ConvNets.
Layer normalization은 애초에 cnn을 위해 나온 방법이 아니다. 논문에서도 cnn을 적용했지만 batch norm보다도 안좋은 결과를 얻었다. 논문에서 설명하는 이유는 다음과 같다.
FCN에서는 각 activation이 loss에 미치는 영향이 비슷비슷해서(즉 통계량이 비슷해서) 모든 feature를 다 합쳐서 하나의 평균과 분산을 구해도 잘 돌아갔는데, cnn은 activation map의 가장자리와 중앙 부분의 통계량이 다르다는 것이다. 가장자리는 잘 fire되지 않으므로 상대적으로 mean이 낮을 거라는 말인 것 같다. 그런데, 그런 pixel별 location 정보는 BN도 활용하지 않는다. BN도 각 채널별로 평균을 매기므로 그 과정에서 위치 정보는 사라진다. Layer norm보다 batch norm이 더 잘되는지 이걸로는 설명되지 않는다.

사실 layer normalization 논문에서는 cnn에 정확히 어떻게 적용했는지 나오지 않는다. 그 이후에 나온 group normalization이라는 논문을 보면 자세한 설명을 볼 수 있다.

복잡해 보이지만 아주 단순 무식한 방법으로, 모든 activation map들의 모든 원소를 다 합쳐서 하나의 mean을 구하는 것이다.
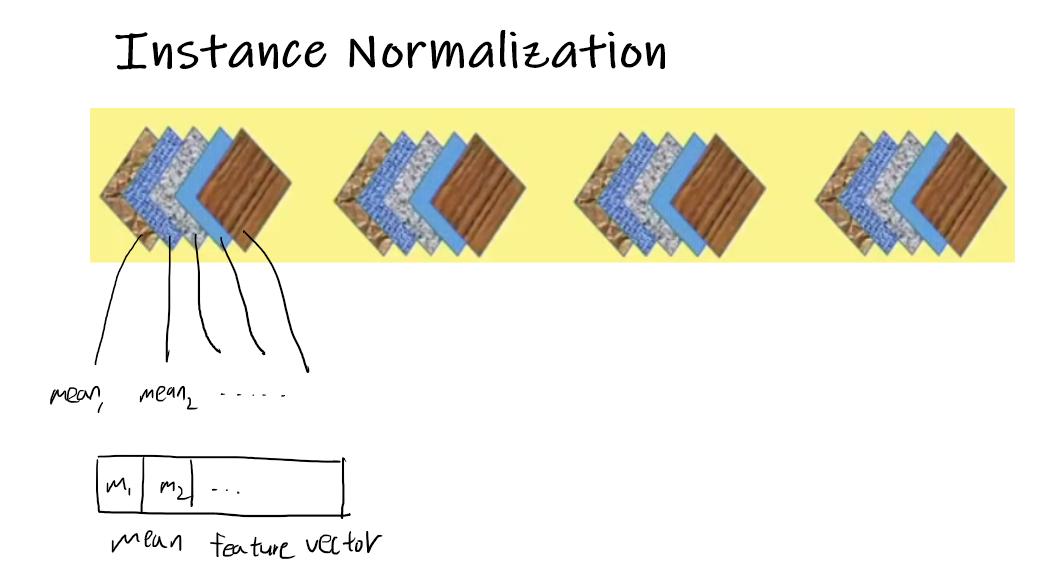
Instance normalization은 좀 더 말이 되는 방법을 사용한다. 하나의 sample로만 통계량을 뽑는다는 점은 layer normalization과 같으나, 전체에 대해 하나의 mean을 뽑는게 아니라 각 채널별로 통계량을 각각 뽑는다.
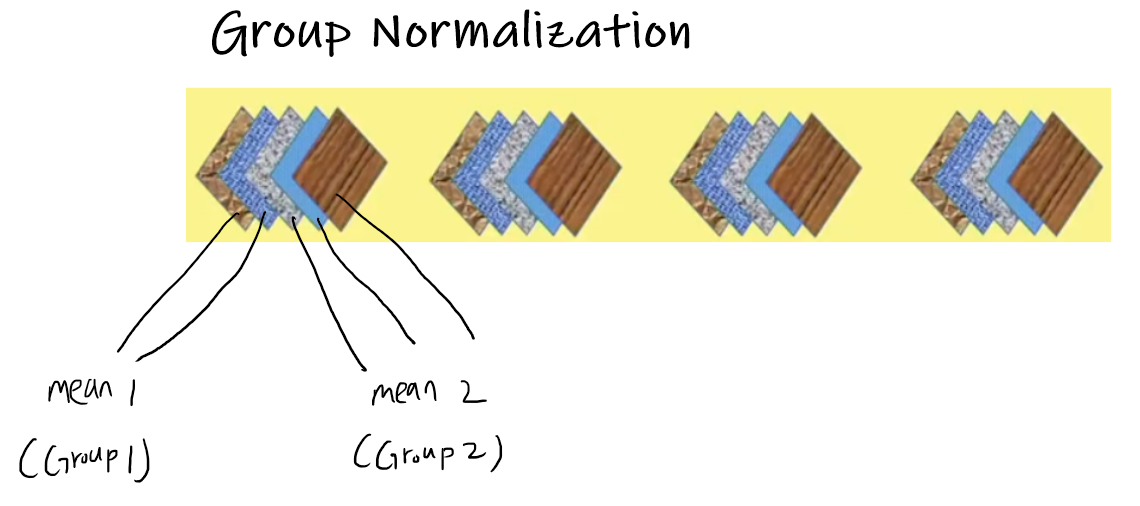
Group normalization은 layer normalization과 instance normalization의 중간 형태로 보면 된다. 채널들을 group으로 묶고, 각 group에서는 통계량이 같다고 가정하는 것이다. 여기서 group의 개수가 1개이면 모든 채널들의 통계량이 같다고 가정하는 layer normalization이 되는 것이고, group의 개수가 채널의 개수이면 모든 채널들이 서로 통계량이 다르다고 가정하는 instance normalization이 되는 것이다.
즉, layer normalization과 instance normalization은 group normalization의 극단적인 두 예시이다.