Knowledge Tracing
Knowledge Tracing(KT)이란 학습자의 과거 performance를 바탕으로 학습자의 지식 수준을 모델링하여 future performance를 예측하는 domain이다. 학습자의 지식 수준을 모델링 할 수 있다는 것은 1:1 맞춤형 교육 서비스를 제공할 수 있다는 것을 의미한다. 이 논문에서 몇가지 사례도 보여준다.
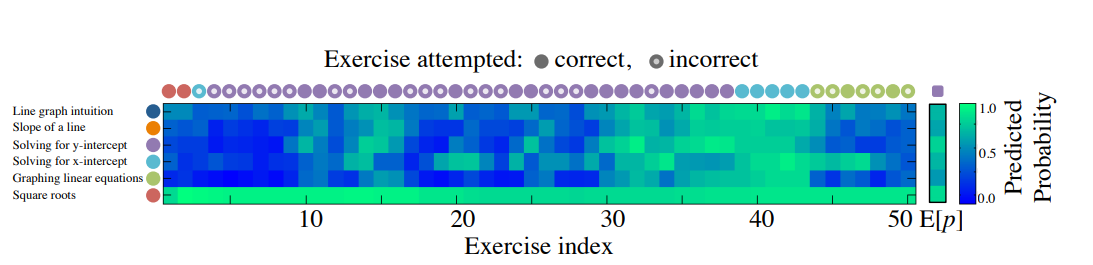
한 학생이 50개의 Khan Academy 문제를 풀 때의 predicted response를 그림으로 나타낸 것이다. Timestep 4~10을 보면 학생이 y-intercept 문제를 계속 틀리니까 색이 파랗다가, 두 번 연달아 맞으면서 초록색으로 바뀌는 것을 볼 수 있다. 모델이 학생의 과거 interaction을 바탕으로 지식 수준을 모델링 하고 있는 것이다.
Contribution
1. KT에서 처음으로 deep learning을 적용하여 좋은 결과를 얻었다.
2. 학습 과정에서 expert annotation이 필요없다.
3. Educational application에서 KT 모델이 유용한 사례를 보였다.
Model
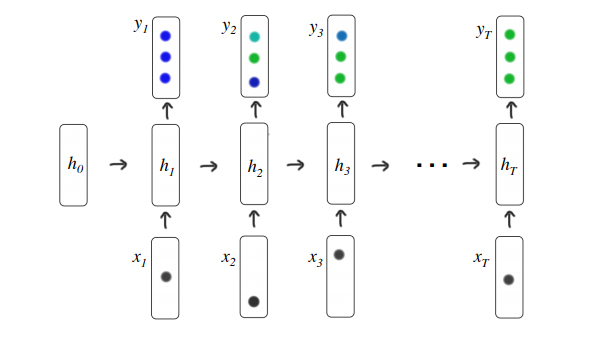
x는 해당 timestep에서의 interaction을 의미한다.
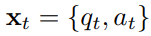
위와 같이 정의하고, q와 a는 각각 t번째 timestep에서의 exercise category와 그 문제에 대한 correctness이다. a는 0 혹은 1이다. 이런 시계열 input을 RNN 혹은 LSTM에 넣고, 나온 output을 fcn에 넣어서 최종적으로 y를 뽑아낸다. y의 dimension은 exercise category의 수이다. 가령, y가 [0.9, 0.9, 0.2, 0.1, 0.1]이라는 것은 학생이 5개 카테고리의 문제를 맞출 확률을 각각 의미하는 것이다.
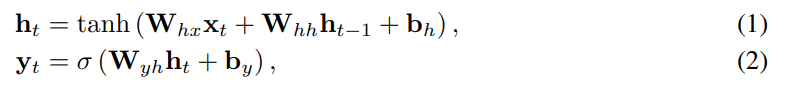
전형적인 RNN의 notation이다.
Loss
우선 x를 (2 x exercise category의 수) dimension으로 one-hot encoding해서 input으로 준다. 인코딩된 x 벡터에는 어떤 문제에 관한 interaction인지, 그리고 맞았는지 틀렸는지의 정보가 담겨있다.
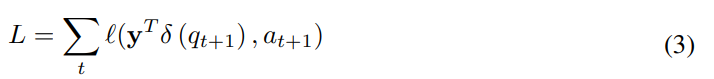
이후에 위와 같은 loss를 학습하게 된다.
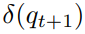
이것은 q를 one-hot encoding 했다는 의미이다. 이 one-hot 벡터가 t번째 timestep의 y벡터와 곱해지면서, y의 예측값 중 t+1번째 q에 해당하는 값만 남기고 나머지 예측값을 0으로 만든다.
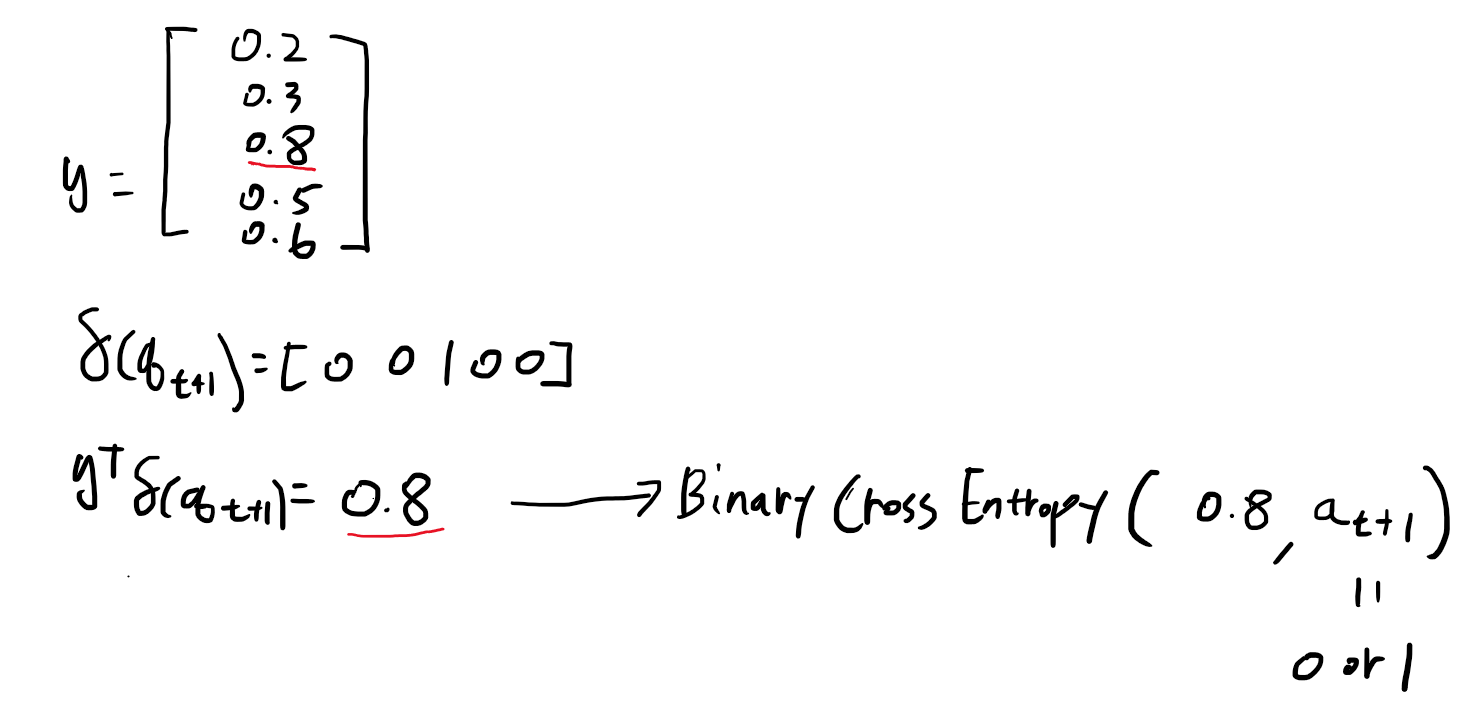
위와 같이 정리할 수 있을 것이다. 즉, t개의 interaction 정보를 바탕으로 t+1번째 문제에 대한 user correctness를 예측하라고 모델에게 요구하는 것이다.
Educational Applications
이런 KT기술을 가지고 커리큘럼을 개선시킬 수 있다.
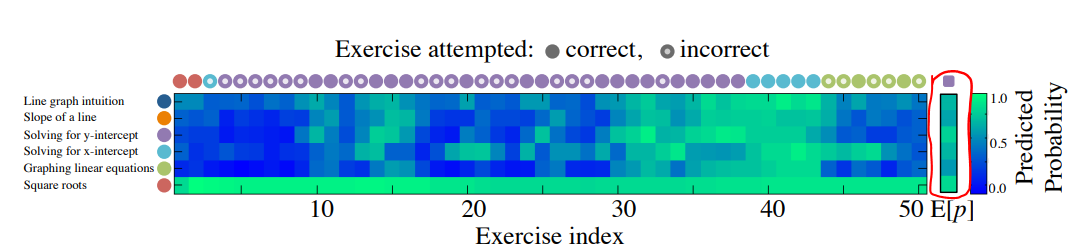
이 그림에서 오른쪽 빨간 박스가 쳐져있는 열을 주목하자. 우리가 성공적으로 지식 수준을 모델링 할 수 있다면, 51번째로 어떤 문제를 풀어야 학생의 지식 수준이 가장 향상될지 예측할 수 있을 것이다. 위 예시에서는 51번째 timestep으로 학생이 y-intercept 문제를 풀어서 맞았다는 정보를 넣어준 뒤 모델의 output인 y벡터를 뽑아서 시각화 한것이다. 기존에 있던 파란 픽셀들이 많이 초록색으로 바뀌면서, 학생이 전체 문제에 대해 정답을 맞출 확률이 전반적으로 높아졌고, 따라서 지식 수준이 향상될 것임을 알 수 있다.
문제간의 관계를 찾는 것도 가능하다.
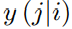
i 문제를 푼 뒤 j를 풀었을 때 정답을 맞출 확률을 위와 같이 정의하면,
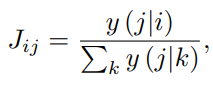
위와 같이 i와 j의 관계를 나타낼 수 있다. 어떤 문제의 쌍 (i,j)에 대해 J값이 높다는 것은 i를 풀고 j를 풀었을 때 맞출 확률이 높다는 의미로, 다시 말해 i문제가 j문제의 선수지식을 다루고 있다는 것이다.
Result
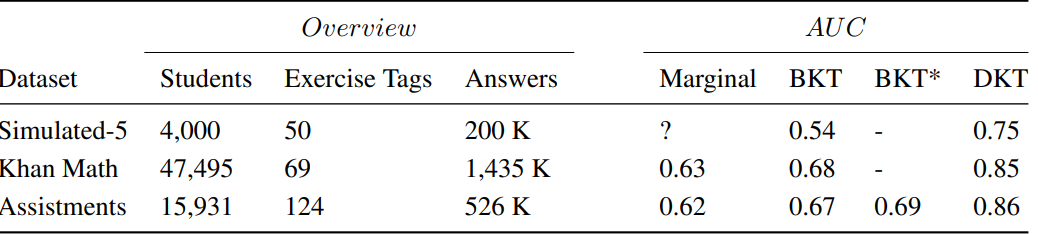
논문에서 주장하는 벤치마크 결과는 위와 같다.
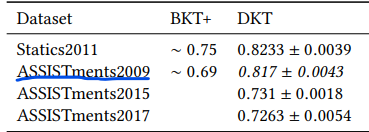
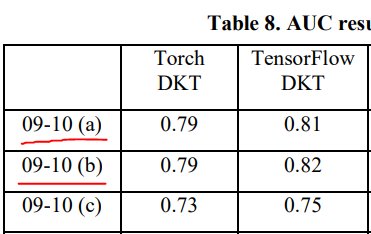
이후 후속 논문들이 재현한 결과는 위와 같다. ASSISTments2009에서 0.81 정도의 auc를 보여준다고 생각하면 될 것 같다. Going Deeper with Deep Knowledge Tracing에서는 ASSISTments2009이 중복된 데이터를 포함하는 문제가 있었고 중복을 제거하면 DKT의 성능이 상당히 떨어진다고 말한다. 하지만 그 뒤에 나온 논문에서도 데이터셋을 그대로 사용하는 경우가 있기 때문에 완전히 결론이 난 문제는 아닌 듯 보인다.
'논문 리뷰' 카테고리의 다른 글
| U-GAT-IT 리뷰 (0) | 2021.01.09 |
|---|---|
| VDSR 리뷰 (0) | 2021.01.02 |
| StarGAN 리뷰 (0) | 2020.12.20 |
| CycleGAN 리뷰 (0) | 2020.11.15 |
| Pix2pix 리뷰 (1) | 2020.11.05 |



