- Conference : CVPR
- Submisson : 2016
- Paper Link : arxiv.org/abs/1609.05158
Keywords
- Single image super resolution
- Sub-pixel convolutional neural network
Contribution
- LR 이미지를 upsampling 없이 바로 CNN에 넣어줌으로써 계산 비용을 줄였다.
- Learnable한 upscaling 방식을 사용해서 psnr을 높였다.
SRCNN(Image Super-Resolution Using Deep Convolutional Networks)
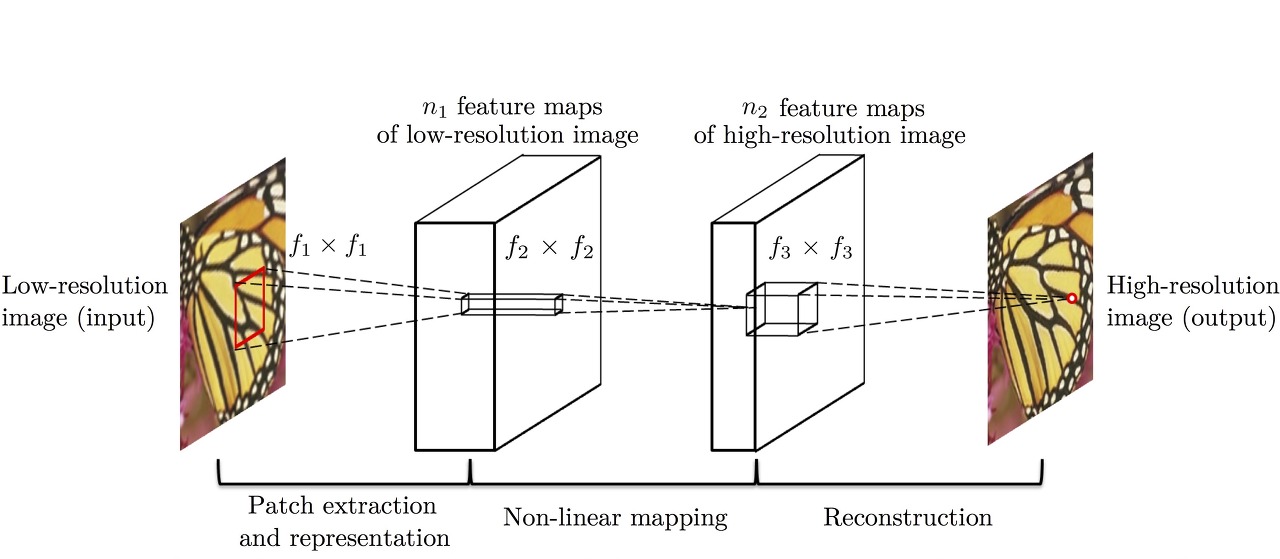
SRCNN은 super resolution에 딥러닝을 처음 적용시켜 좋은 결과를 얻었던 모델이다. 위와 같이 bicubic으로 키운 interpolated low resolution 이미지가 input으로 들어가게 된다.
SRCNN의 문제점
- Bicubic으로 키운 이미지를 인풋으로 넣기 때문에 연산량이 많다.
- Bicubic으로 키우면서 정보량은 전혀 늘어나지 않는다. 즉, upsampling 방식이 learnable하지 않다.
Architecture

Figure가 상당히 직관적인데, H x W x C인 LR image를 H x W x Cr^2 으로 만들고, 펼쳐서 이걸 rH x rW x C로 만든다. 마지막 layer의 feature map들을 펼쳐서 upscaling하게 된다. 마지막 sub-pixel layer를 제외하면 구조적으로 특별한 점은 없다.
Loss

MSE를 사용한다.
Results

Run time이 SRCNN에 비해 10배 이상 빠른 것을 확인할 수 있다. Video super resolution에서 scale factor를 4로 했을 때 거의 15배 빠르다고 한다.
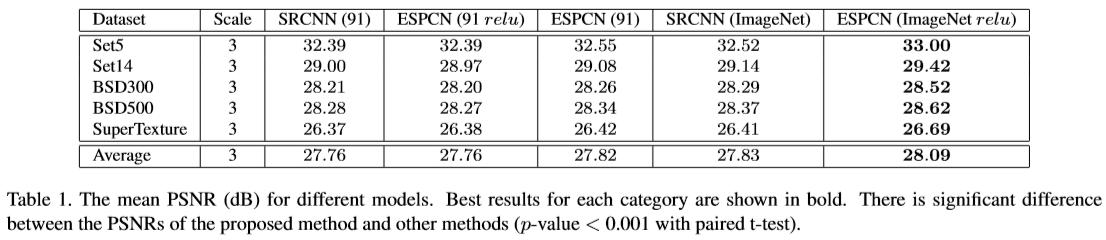
Efficiency를 강조한 만큼 psnr은 크게 차이나지 않는다.
Implementation details
- Number of layers : 3
- Fileter size : 5-3-3
- Number of filters : 64-63-r*r
- Number of epochs : 100
- Learning rate : 0.01~0.0001
- YCbCr에서 휘도 값만 사용함.
- Cropped by 17r x 17r for GT image, no overlap.
- Relu보다 tanh가 성능이 좋았음.

'논문 리뷰' 카테고리의 다른 글
| Fast R-CNN 리뷰 (0) | 2020.10.25 |
|---|---|
| SPPnet(Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition) (0) | 2020.10.07 |
| R CNN(Rich feature hierarchies for accurate object detection and semantic segmentation) (0) | 2020.09.30 |
| A Neural Algorithm of Artistic Style 구현 (0) | 2020.09.14 |
| A Neural Algorithm of Artistic Style (0) | 2020.09.13 |



