CS231n Lecture 13 : Generative Models

Unsupervised learning에는 label이 없다. 대신 데이터 자체의 hidden structure를 학습한다.




Unsupervised learning을 푸는 것 만으로 visual world의 underlying structure를 알게 된다. 가령 자기 자신을 복원시키는 오토 인코더는 실제 데이터의 의미있는 feature를 찾아낼 수 있다.

Generative model의 목적은 데이터의 density를 닮는 것이다. 다양한 곳에 적용할 수 있는데, 시계열 데이터를 생성해서 RL에 사용할 수 있다고 한다. 또한 latent representation을 배우는 것도 유용하다.
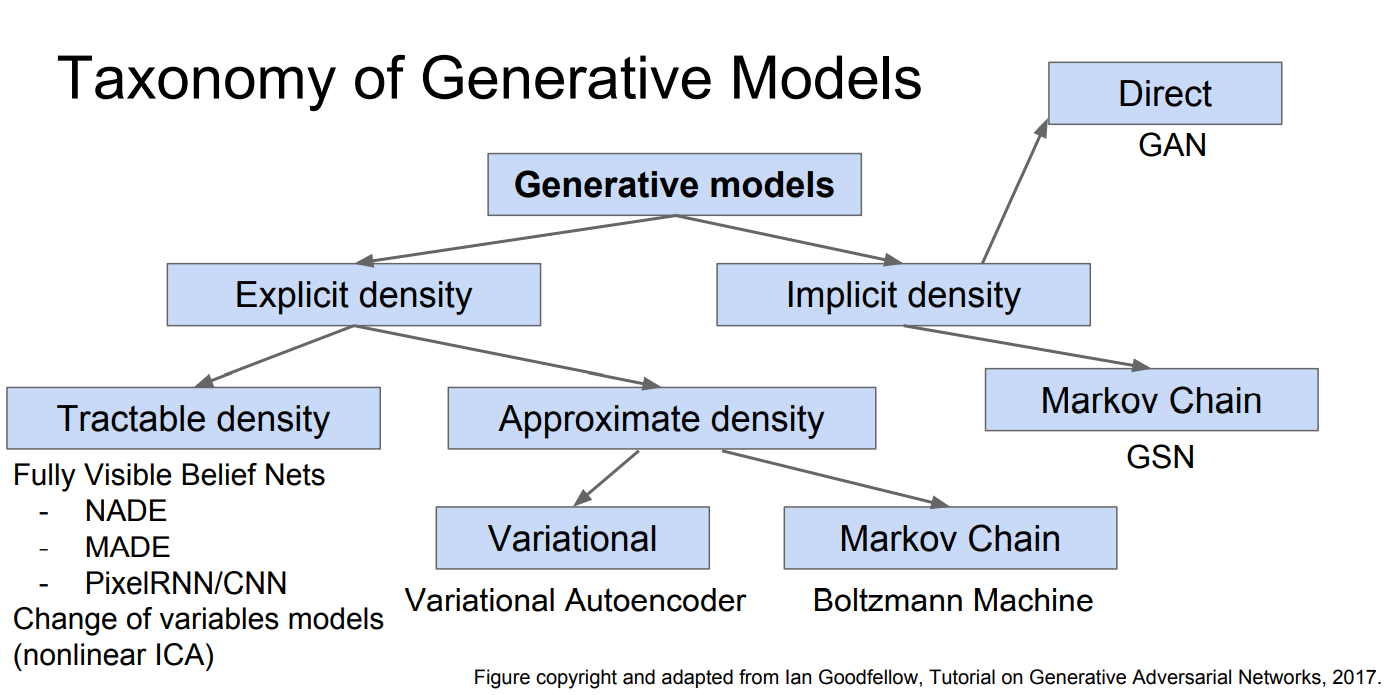
갈래는 위와 같이 나눠진다. Explicit density 모델에서는 likelihood p(x)가 명확하게 정의되고 그에 따른 training data의 label도 존재해서 loss를 분명하게 정의할 수 있다. 따라서 그 loss를 보고 학습 정도를 알 수도 있다. 하지만 implicit density 모델은 그렇지 않다.

Explicit density model은 training data의 likelihood를 높이는 방향으로 학습한다. 어떤 이미지가 등장할 likelihood는 그 이미지의 각 pixel이 등장할 확률의 곱으로 나타낼 수가 있다.

가령 2 x 2 이미지의 likelihood는 위와 같이 나타낼 수 있다. 물론 여기서는 각 픽셀이 등장하는 사건이 서로 독립이라고 가정한 것이고, 현실에서는 어떤 픽셀은 다른 픽셀에 종속되므로 generator는 이전의 픽셀들을 고려해서 다음 픽셀을 만들 것이다. 그러므로 슬라이드에서는 condition term이 들어가 있다. 그럼 대체 training data의 likelihood를 최대화 한다는 것은 무슨 뜻일까?

우리가 학습시키려는 모델은 이미지 x를 생성하는데, 그 각 이미지가 나올 likelihood를 위처럼 그래프로 나타낼 수 있을 것이다. 그런데 생성 모델이 잘 한다는 것은 생성한 이미지 x가 training data이면 정말 잘하는 것이다(실제로는 비슷하되 약간 다른 이미지를 원하지만). 우리가 x를 뽑았는데 뽑는 족족 training data이면 얼마나 좋겠는가? 가령 얼굴 생성 모델이 뽑는 족족 사람 얼굴을 생성하면 좋을 것이고, 자동차 이미지를 생성하면 벌을 줘야 할 것이다. 그래서 x가 training data일 likelihood는 최대화하고, x가 training data가 아닐 likelihood는 최소화 하는 것이다.

픽셀은 다른 픽셀에 종속되므로 context를 고려해야 하는데, RNN에 넣어보자는 아이디어이다. 위와 같이 순차적으로 생성하므로 느리다.

그래서 CNN을 사용해서 보다 빠르게 생성한다.

모델은 위와 같이, context 정보를 바탕으로 다음 픽셀을 예측하는데, 위와 같이 255개의 class에 대한 classification을 한다. 그리고 ground truth image의 픽셀과 생성 모델이 만들어낸 픽셀을 비교한다. 여기서 softmax loss를 적용하면 모델이 GT의 pixel value가 나올 likelihood(softmax value)를 최대화 하는 방향으로 학습할 것이다. 여기서 pixel을 생성할 때는 convolution을 동시에 병렬로 연산할 수 있어서 괜찮지만, test 시에는 한 patch가 다 만들어져야 다른 patch를 생성할 수 있다. 여전히 순차적이므로 느리다.

이제 implicit density model로 넘어왔다. 위 적분 수식을 이해하기 쉽게 하기 위해 total probability를 이용하였다.

VAE를 이야기하기에 앞서 오토 인코더를 설명한다. 오토 인코더는 자기 자신을 복원하는 것을 학습한다. Encoder는 이미지의 유용한 feature를 배우기 때문에 supervised learning로 transfer해서 사용할 수도 있고 용도가 다양하다.

VAE에서 z는 continuous한 latent vector이므로 likelihood가 intractable하다.

Integral없이 p(x)를 구할 수는 없을까? 위와 같이 posterior density를 써놓고 보면, p(z|x)만 있으면 p(x)를 구할 수 있을 것 같다. Encoder를 만들어서 p(z|x)를 근사하게 하자.



이 부분은 나중에 다시 살펴보자. 이 이후로 vanila gan이랑 dcgan 정도를 다루는데 생략하겠다.
VAE는 gan에 비해 blurry한 이미지를 생성하지만, 둘을 합친 연구도 많이 나오고 있다.