CS231N Spring 2020 Assignment1 : Two Layer Net

간단한 값들을 가지고 우선 모델의 순전파와 역전파를 구현할 것이다.

이 부분을 implement 하면 된다. 순전파야 단순히 output을 다음 layer의 input으로 주는 구조이므로 어려울 것이 없고, 역전파도 softmax 과제를 잘 했다면 비슷한 방식으로 쉽게 할 수 있다. yun905.tistory.com/11 를 참고하자. 다만 한 가지 다른 부분은 이전 과제에서는 bias trick을 사용해 W에 bias를 끼워넣어서 따로 역전파를 계산해 주지 않아도 되었는데, 여기서는 b가 따로 떨어져 있으므로 계산을 해주어야 한다.
Bias는 각 class별로 1개씩 존재하므로 shape이 score(L2).shape[1]과 같을 것이다. 이런 하나의 bias가 X.shape[0]개의 data에 대해 각각 한 번씩 더해진다. 우리가 computational graph를 계산할 때 branch 부분, 즉 이렇게 갈라지는 부분은 각각 가지에 대한 역전파를 구한 후 마지막에 sum 해주었던 것을 떠올리자. 하나의 bias는 X.shape[0] = num_data 개로 갈라진다. 그리고 bias는 더해지므로 local gradient는 1이다. 이 사실들을 이용하면 쉽게 해결할 수 있을 것이다.


Loss와 gradient는 이상이 없다.

Batch size만큼 추출해서 SGD를 사용하는 부분을 구현하자. 단순히 learning rate에 gradient를 곱한 후 parameter에서 빼주면 된다.

Accuracy를 구하기 위해 꼭 필요한 함수이다. 간단하게 구현할 수 있다.

우리의 toy data와 toy parameters가 잘 작동하는 것을 확인했다. 본격적으로 CIFAR-10에 적용해보자.

데이터를 위와 같이 분할하여 사용할 것이다. 결과를 보면 오히려 single layer때보다 성능이 안좋다. 사실 딥러닝을 처음 접하는 사람들이 다들 겪는 문제이다. 나도 처음에 mnist 예제를 학습할 때 오히려 single layer보다 성능이 떨어졌던 기억이 있다. 이유가 무엇일까?
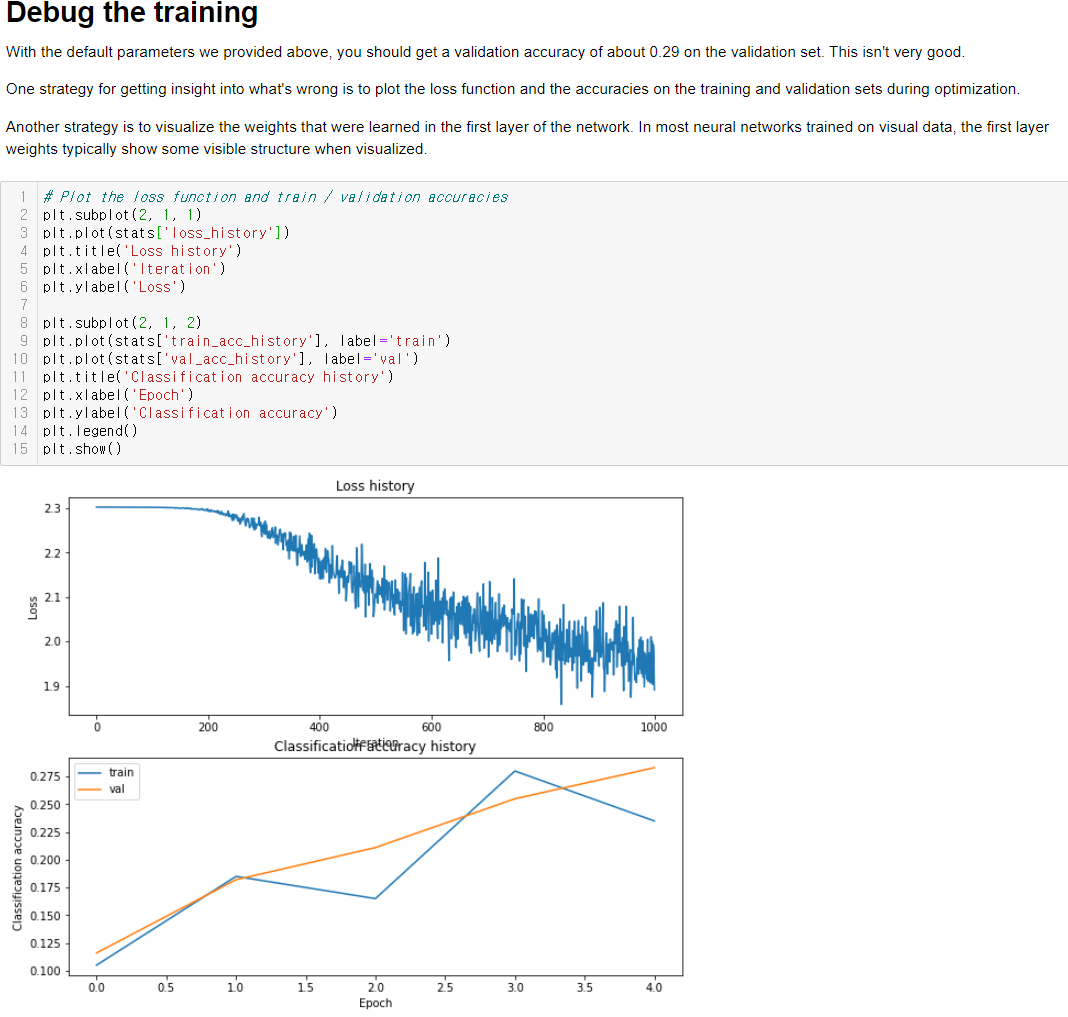
Loss와 accuracy를 visualize 하는 것은 아주 유용한 디버깅 툴이다.
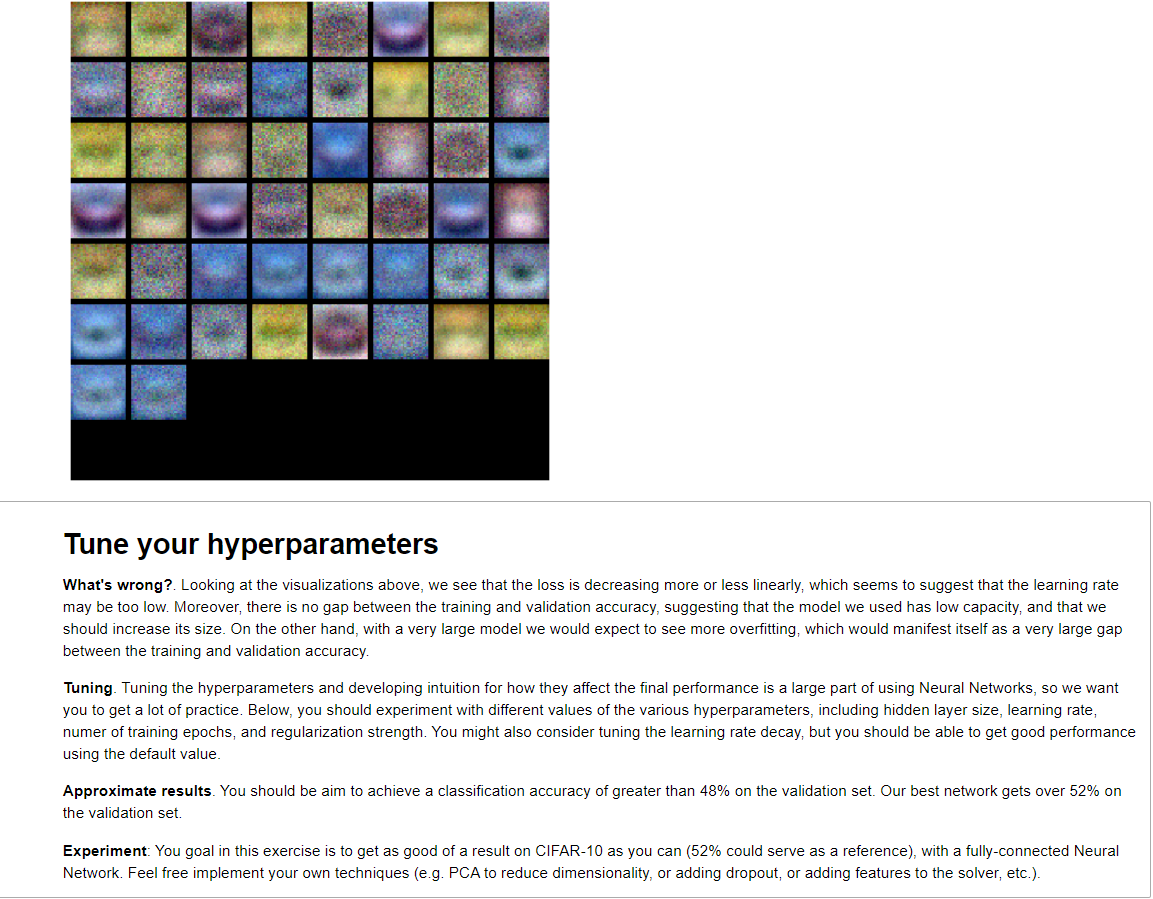
또한 W1을 시각화 하는 것도 유용하다. Single layer에서 보았듯이 첫 층의 W들은 해당하는 class의 template 형상을 보이기 마련인데, 약간 흐릿하다. 이걸 튜닝해서 48% 이상의 validation accuracy를 만드는게 목표이다. 일단 처음 떠오르는 생각은
1. 내 생각에는 우선 loss가 많이 떨리지만 잘 감소하고 있고 accuracy도 잘 올라가고 있다.
2. 이전 과제에서도 template이 흐릿할 때 iteration 수를 높여주니까 해결이 되었다.
3. Overfitting도 아직 안보이므로 더 학습시켜서 손해볼 게 없다.
우선은 iteration을 높여보자.


Iteration을 1000에서 2000으로 올려주니 validation accuracy가 0.368로 8%가량 올랐다. W1도 비교적 뚜렷한 모양을 보인다. 그런데 loss가 어느정도 수렴하는 모습이라서 더 학습을 진행해도 큰 효과를 보기는 힘들것 같다. 아직도 overfitting은 보이지 않으므로 hidden_size를 4배 높여보겠다.

Hidden size를 50에서 200으로 높였고 accuracy는 0.365가 나왔다. Parameter 수를 늘려도 overfitting이 보이지 않으므로 regularization strength를 높이 가져갈 이유가 없다. 이걸 대폭 깎아보겠다. 그 결과 0.372의 accuracy를 얻었다.
Learning rate이 거의 가장 중요함에도 불구하고 한 번도 건들이지 않았다. Guideline을 보면 learning rate가 너무 낮아 보인다고 하는데, 내 생각은 반대다. Loss가 들쑥날쑥한 모습을 보이는게 마치 아래의 사진과 같아 보이기 때문이다. 난 반대로 learning rate가 너무 높다는 의심이 든다.
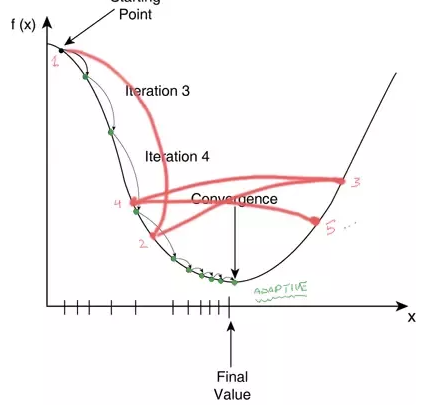
일단 guide에서 그렇게 얘기 하니까 한번 decay를 0.95에서 0.97로 늘려서 간접적으로 learning rate를 높이는 효과를 볼 것이다.

Iteration도 3000으로 늘려주었다. 결과가 대폭 좋아졌다. 혹시 decay를 그대로 두어도 3000 iteration을 돌리면 좋아졌을까?

별반 차이가 없는걸로 봐서 decay의 영향이 아니라 iteration을 늘려준 탓에 성능이 올라간 것 같다. 그러면 decay는 그대로 0.95에 두고, iteration만 계속 올려서 상한이 어디인지 확인하겠다. Validation accuracy가 떨어지기 전까지는 iteration은 높으면 높을수록 좋기 때문이다.

대략 한 10000 iteration부터 accuracy가 멈춘다. 대략 0.462정도. 10000을 상한으로 둘 것이다. 저렇게 많이 학습을 시켜도 overfitting이 안오는 것을 확인할 수 있다. Hidden size를 더 늘리는 것을 고민해 봐야겠다. 우선은 아까 의심된다고 했던게 learning rate이 너무 크다는 거였다. Decay를 0.92로 낮춰보겠다. 결과는 0.432이다. Decay를 낮춘건 좋은 선택은 아닌 것 같다.
이 모델은 2만번 학습시켜도 overfitting이 발생하지 않는다. Hidden size를 늘렸지만 아직도 너무 단순하다는 얘기인 것 같다. 한번 overfitting을 의도적으로 일으켜 보겠다. Hidden size를 800으로 늘렸다.

0.474가 나왔다. 조금만 더 높이면 된다. Hidden size를 1200으로 늘려보겠다.
결과는 0.476으로 차이가 없었다.
이제와서 생각해보니 모델이 복잡도가 떨어지는 것도 있지만 그냥 underfit 된 탓이 큰 것 같다. 그리고 loss도 어떻게 보면 들쑥날쑥 하면서도 우하향 하고 있는데, 그러면 learning rate을 좀 더 높여볼 여지가 있다는 말도 이해가 간다. 이번에는 decay를 수정하는게 아니라 초기값을 10배 높여보겠다.

0.555라는 정확도를 보여줬다. Overfitting이 보이므로 hidden size도 다시 800으로 낮출 것이다.

최종적으로 validation accuracy는 0.56을 기록했고, 더 만져볼 여지가 있지만(특히 overfitting 관련해서) base line을 훨씬 넘겼으니 슬슬 test로 넘어가자.

이전 과제들처럼 iteration을 돌리면서 hyperparameter를 선택하는 방법을 추천했지만, 이미 손수 튜닝을 끝냈기 때문에 바로 이 모델로 돌릴 것이다.

성공적이다.

Hidden size 를 늘렸기 때문에 W가 어떤 구체적인 class의 형상을 보여주진 않는다.

다른 과제들에 비해 inline question이 어렵지 않았다.