CS231n 2017 Lecture 5 : Convolutional Neural Networks

Neural Network와 CNN의 역사를 먼저 짚고 넘어간다. Mark 1 Perceptron은 perceptron을 최초로 구현한 기계이다. Update rule이 있었지만 backprop은 없던 시절.

여러 층의 layer을 쌓았던 기계이지만 backprop은 아직 없다.

Chain rule을 이용한 backprop의 발견.

크고 깊은 네트워크의 등장. 하지만 아주 신중하게 weight를 초기화 하지 않으면 학습을 시킬 수 없었다. Weight 초기화 방식도 번거롭고 복잡했다.

Strong result가 나온건 2010년 이후, speech recognition과 image recognition에서 성능이 좋았다. AlexNet이 등장했다.

Hubel과 Wiesel의 고양이 뇌 실험. 알아낸 사실들은 다음과 같은데,

빛을 받아들일 때 그 세포의 위치와 그 세포가 활성화되는 빛의 속성이 관계가 있다. 오른쪽 사진을 보면 중앙부에 위치한 세포들이 빨간색을, 가장자리에 위치한 세포들이 파란색에 반응하는 것을 볼 수 있다.

또한 뉴런들은 계층 구조를 가지고 있고, 단순한 feature들을 더 깊은 계층으로 전달하여 복잡한 feature를 얻어낸다.

이런 사실을 바탕으로 1998년 CNN이 등장, document recognition, 그 중에서도 digit recognition을 꽤 잘했으며 우체국에서 우편 번호 인식에 많이 쓰였다. 그런데 더 복잡한 이미지를 인식하는 것은 힘들었다.
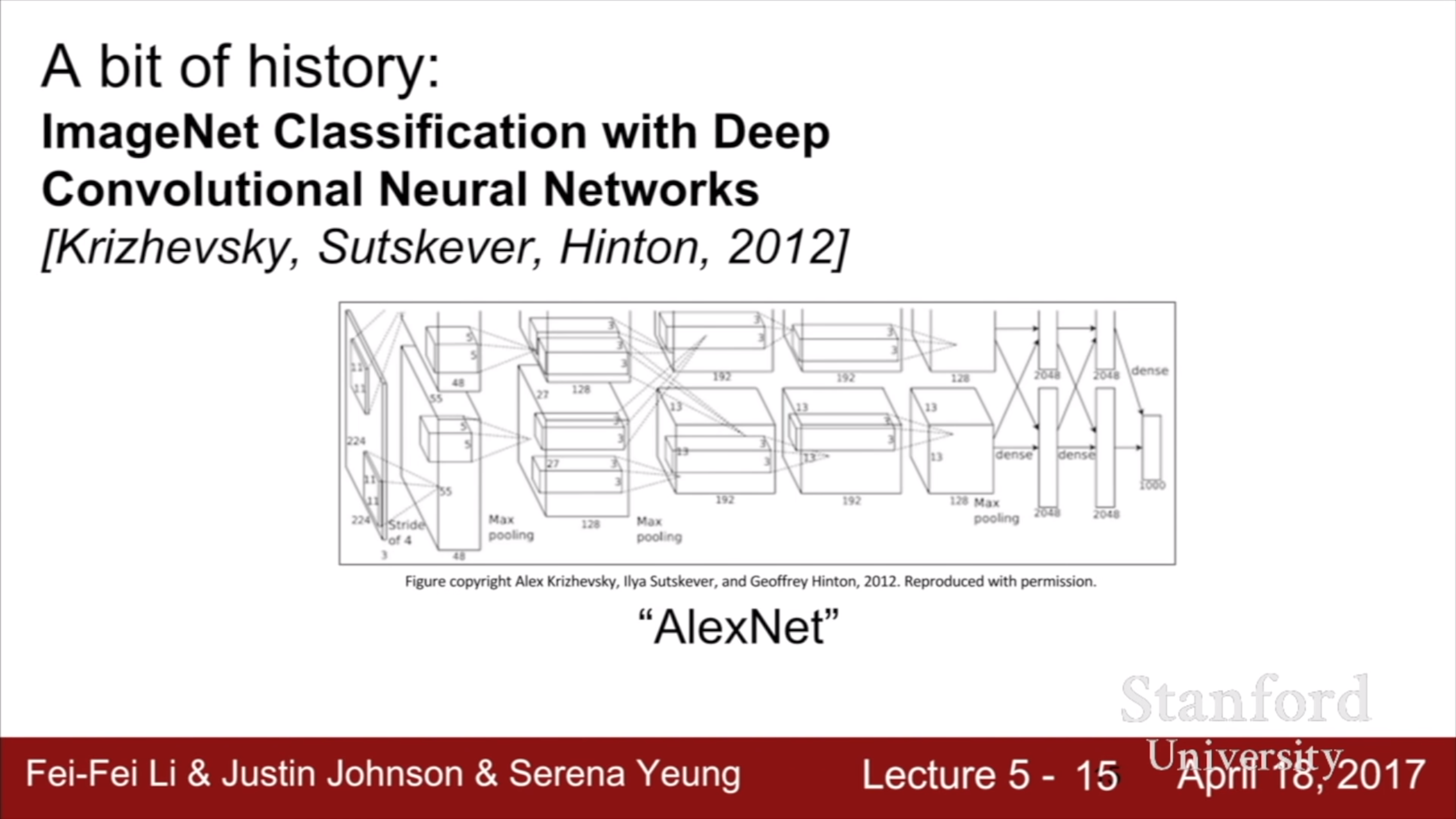
그리고 나온 AlexNet, 1998년 CNN과 크게 달라보이지 않는다. 이것에 대해서는 이전 강의에서도 다룬 바 있다.

FCN에 이미지를 넣을 때 reshape해서 matrix로 펼쳐서 넣었다. CNN에서는 data의 공간적 구조를 유지한다. Data와 같은 depth를 가진 필터가 그 이미지를 slide 하면서 dot 연산을 한다.

CNN이 연산하는 것을 이해하려면 이런 이미지도 좋지만 gif으로 된 자료들을 보는게 나을 것이다. 필터 하나 당 b도 하나임을 알고 넘어가자. 필터가 이미지와 겹쳐서 일어나는 dot product를 matmul로 구현하려고 W에 T를 붙인 것이다.

필터의 개수가 output의 depth가 된다. 각 필터가 추출해내는 feature가 다를것이므로 우리는 여러 개의 필터를 쓸 것이다.

CNN을 쌓는 것은 단순히 이전 layer의 output을 다음 layer의 input으로 넘겨주는 것이다. Output을 넘겨주기 전에 비선형 함수를 통과시킨다. 그리고 선택적으로 마지막에 FCN을 얹어서 classification 등을 할 수도 있다.

깊은 layer의 필터는 더 복잡한 feature를 추출한다. 위에서 언급한 고양이 뇌 실험의 결과와 일맥상통하는 부분이다.

필터를 거친 output의 크기를 계산하는 식이다.

Output size를 유지하기 위해 zero padding을 할 수 있다. 모델이 deep 해지면 CNN을 거치면서 output size가 많이 줄어들 것이기 때문이다. 필터가 slide하면서 이미지의 중앙 부분에 비해 가장자리는 많이 거치지 않는데, zero padding이 이미지의 가장자리를 약간 중앙으로 옮겨줘서 이 부분도 해결해 줄 수 있다. Output size를 계산할 때 padding 한 만큼 N을 증가시켜서 계산한다.
반대로 output size를 줄이기 위한 방법으로 pooling이 있고, 요즘은 stride를 늘리는 방법을 많이 사용한다.

Output size 맞추는 간단한 퀴즈. 이건 쉬웠는데, 여기서 parameter 개수를 물어본다. 75개짜리 필터가 10개 있으므로 750이라고 생각하기 쉬운데, bias를 잊으면 안된다. 필터 하나 당 bias 하나이므로 760이 정답이다.

간단한 summary 이후에 자주 쓰이는 필터 크기를 보여준다. 필터 크기는 3이랑 5가 많이 쓰이고, padding은 원하는 size에 맞게 뭐든지 가능하다고 한다. 필터 크기가 1이여도 문제 될 건 없다.

Pooling layer. 아까 언급했다시피 output size를 줄이는 효과가 있고 모델에 invariance를 준다. 가령 maxpool을 한다고 할 때, 최고 값이 아닌 다른 값들이 조금씩 변한다고 해도 output은 똑같을 것이다. Maxpooling이 자주 쓰이는 이유에 대해서도 설명하는데, image recognition을 할 때 한 개의 필터는 이미지의 어떤 aspect를 찾고 있다고 봐도 된다. 그 필터와 dot 연산 결과는 그 필터가 그 위치에서 얼마나 활성화 되었는가에 대한 값이다. Maxpooling을 했을 때는 그 필터가 그 region에서 얼마나 활성화 되었는가 라는 의미로 볼 수 있다. 그러면 averagepooling은 그 필터가 그 region에서 평균적으로 얼마나 활성화 되었는가 라는 의미이므로 averagepooling도 충분히 말이 되지 않을까? 최근에 읽은 논문에서도 maxpooling이 gradient flow에 방해되므로 averagepooling을 사용했다는 언급이 있었던 만큼, 둘 다 합리적인 방법인 듯 하다.
CNN까지의 history와 전체적인 CNN의 구조에 대해 알아보았다.